Comparison: Webhooks vs. Periodic Polling For Data Pipeline Resilience (Ref: Stripe)
Introduction
If you work in data analysis, you know the feeling. Your dashboard was perfect on Tuesday. On Wednesday, the Sales Director slacks you: "The lead count in Looker doesn't match Salesforce." You dig in, and you find five missing records. They weren't filtered out; they simply never arrived in your data warehouse.
Usually, this is the result of relying solely on real-time automation triggers (Webhooks) for data ingestion. While the modern data stack pushes for "real-time everything," I have observed that for Data Analysts prioritizing governance and auditing, real-time is often the enemy of reliability.
This article compares two fundamental architectural patterns for moving data from operational tools (like CRMs or ERPs) to analytical storage (like Snowflake or Google Sheets) using low-code tools: Event-Driven Webhooks (Push) versus Scheduled Polling (Pull).
We will look at why major API providers like Stripe recommend a hybrid approach to ensure strict financial reporting, and how you can apply this logic to your own data pipelines.
The Core Conflict: Latency vs. Completeness
When we build automations in tools like Make or n8n, the default instinct is to use the "Watch" trigger (a Webhook). It feels efficient. Something happens, and we react.
However, for a Data Analyst, efficiency is secondary to integrity. A missed event in a marketing workflow means a missed email. A missed event in a financial report means a compliance violation.
The Contenders
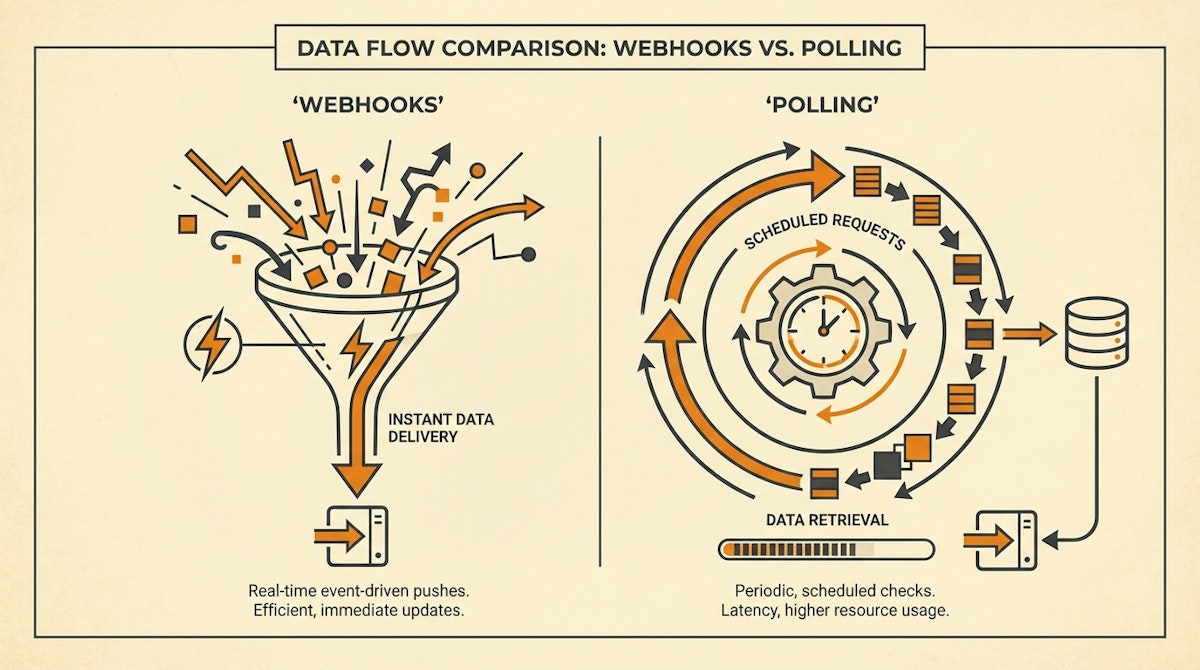
- Webhooks (The Push Model): The source system (e.g., Hubspot) sends a JSON payload to your automation endpoint immediately when an event occurs.
- Periodic Polling (The Pull Model): Your automation wakes up on a schedule (e.g., every 15 minutes), asks the source system, "Give me everything that changed since my last run," and processes the list.
| Feature | Webhooks (Push) | Periodic Polling (Pull) |
|---|---|---|
| Latency | Near Real-Time | Scheduled (Batch) |
| Data Completeness | Best Effort (Risk of Drop) | High (Cursor-based) |
| Bursty Loads | Overwhelms Receiver | Controlled Pace |
| Error Recovery | Complex (Replay logic) | Simple (Re-run batch) |
Deep Dive: The Hidden Risks of Webhooks
Webhooks are excellent for operational actions (sending a Slack notification), but they pose significant governance challenges for reporting.
- The "Fire and Forget" Problem: Most SaaS tools attempt to send a webhook once. If your automation platform (Make/n8n) is down for maintenance or hits a rate limit, that packet is lost. Unless the source system has robust retry logic (which is rare outside of enterprise tools like Stripe), you have a permanent data gap.
- Order is Not Guaranteed: In a high-volume environment, you might receive the "Deal Updated" webhook before the "Deal Created" webhook due to network jitter. This creates race conditions that corrupt your database schema.
- Schema Drift: If the payload structure changes unexpectedly, the webhook listener breaks. You usually find out days later when the reporting numbers don't add up.
Deep Dive: The Governance of Polling
Polling is often viewed as "legacy" or "inefficient" because it involves checking for data even when nothing has happened. However, for a Data Analyst, it provides the control necessary for auditing.
- The Cursor Pattern: By storing the
last_modified_timestampof the previous run, you can requestGET /deals?updated_after={timestamp}. This ensures you never miss a record, even if the automation was down for an hour. When it wakes up, it just fetches a larger batch. - Rate Limit Negotiation: You control the flow. If you are syncing to a database with strict write limits, polling allows you to process 50 records at a time, rather than being flooded by 1,000 simultaneous webhooks.
- Idempotency: It is easier to design a polling sequence to be idempotent (safe to run multiple times). If a run fails halfway, you simply run the query again for the same time window.
The Strategic Compromise: The "Stripe" Pattern
We can look to Stripe for guidance here. In their integration documentation, they suggest listening to webhooks for immediate reactions but relying on periodic reconciliation (polling) for financial truth.
For a resilient data pipeline, I suggest this hybrid architecture:
1. The Alert Layer (Webhooks)
Use webhooks solely for notifications or triggering urgent operational tasks where 99% accuracy is acceptable.
- Example: "New Deal Signed" -> Slack Alert.
2. The Reconciliation Layer (Polling)
Use scheduled polling for the actual ETL (Extract, Transform, Load) process into your data warehouse or BI tool.
- Example: Every hour, query CRM for all deals modified in the last 70 minutes (allowing for a 10-minute overlap/buffer).
- Upsert Logic: When processing this batch, use an "Upsert" (Update or Insert) method based on the Record ID. This heals any data gaps that might have occurred during the hour and corrects any records that changed multiple times.
Conclusion
For the Data Analyst, trust is the currency of the realm. While real-time dashboards are impressive, a reliable dashboard is valuable. By acknowledging the fragility of webhooks and implementing a robust, cursor-based polling mechanism for your primary data pipelines, you shift from reactive bug-fixing to proactive governance.
This approach effectively separates the concern of "Speed" (Webhooks) from the concern of "Truth" (Polling).
References
- https://docs.stripe.com/webhooks/best-practices
- https://segment.com/docs/connections/sources/catalog/

