Stabilizing Data Pipelines With The Metadata Sidecar Process
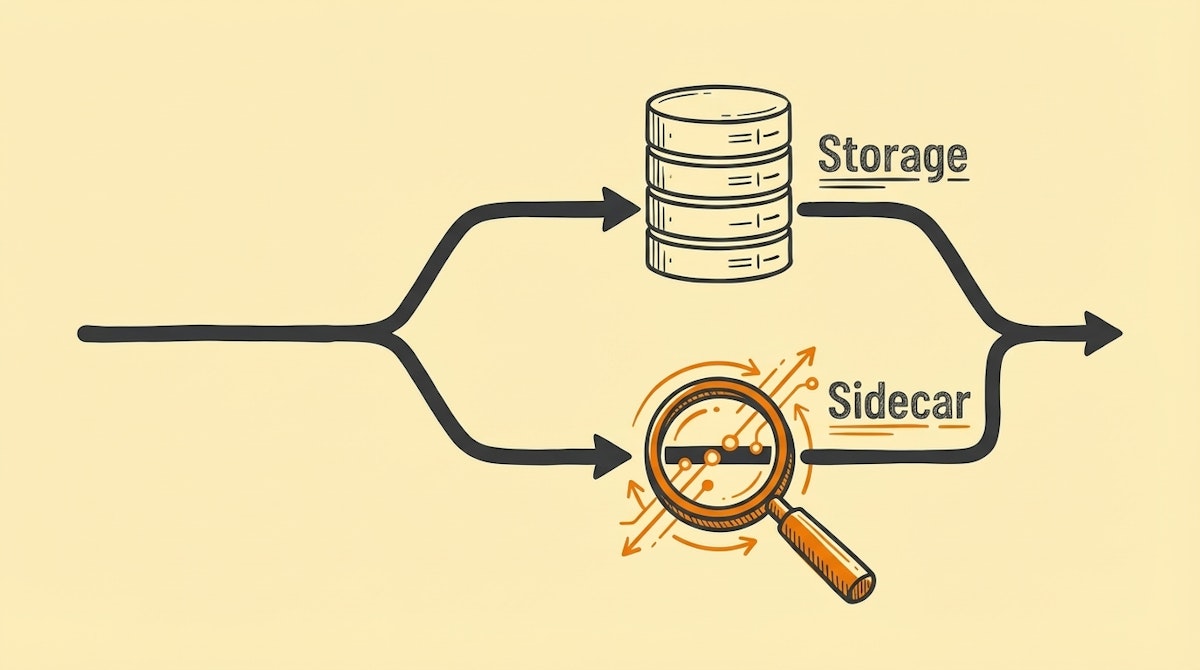
Table of Contents
- The Friction Between Agility and Integrity
- The Hidden Cost of Silent Schema Drift
- The Blueprint: The Metadata Sidecar Process
- Analyzing The Architecture
- Why This Matters for Strategic Alignment
The Friction Between Agility and Integrity
If you work in operations or automation, you likely prioritize speed and functionality. We want to move data from A to B to C as efficiently as possible. However, I have observed a recurring tension when these automated workflows interface with the Data Analytics team.
The Data Analyst has a different directive: truth, consistency, and stability. They aren't just looking for the data to arrive; they are looking for the data to be trustworthy enough to base strategic decisions on.
The conflict arises when we build low-code automations (using tools like Make or n8n) that treat data payloads as flexible, fluid objects. A Data Analyst, conversely, usually relies on rigid schemas within a data warehouse or BI tool like Looker or Tableau. When an automation silently adds a field, changes a data type, or drops a column because an API updated, the automation might report "Success," but the downstream dashboards break—or worse, they display incorrect numbers.
To bridge this gap, I’ve been exploring a structural approach I call The Metadata Sidecar Process.
The Hidden Cost of Silent Schema Drift
In traditional software engineering, changes to data structures are managed through rigorous migrations and version control. In the low-code world, we often lack these guardrails.
I recall seeing workflows where a CRM field name changed from monthly_revenue to mrr. The automation tool adapted dynamically (or just passed null), but the Data Analyst’s SQL queries were hard-coded to the old field. The result was a reporting blackout that lasted days before anyone identified the root cause.
This isn't just a technical annoyance; it creates a "trust deficit." If stakeholders cannot verify the lineage and structure of the data generated by automation, they cannot trust the ROI calculations derived from it.
The Blueprint: The Metadata Sidecar Process
This blueprint does not require complex code, but it does require a shift in how we architect our scenarios. Instead of a single linear path (Source → Transformation → Destination), we introduce a parallel branch—the "Sidecar"—dedicated solely to observing and logging the structure of the data being processed.
This process treats metadata (data about the data) as a first-class citizen, equal in importance to the operational payload itself.
Core Components
- The Operational Stream: This is your standard automation flow. It ingests raw data, applies business logic (e.g., formatting dates, calculating totals), and loads it into the destination (e.g., BigQuery or Postgres).
- The Metadata Sidecar: A parallel branch that triggers simultaneously. It does not process the data for business use. Instead, it extracts structural attributes: key names, data types, row counts, and timestamp of execution.
- The Registry Ledger: A strict, append-only log (hosted in a database or even a structured Airtable base) that records the "health check" of every batch run.
Analyzing The Architecture
The goal here isn't to stop the automation if the schema changes (though you could), but to create an audit trail of structure.
When a dashboard breaks, the Data Analyst doesn't have to dig through API documentation or ask the Ops team what they changed. They simply query the Registry Ledger to see: "Ah, at 14:00 on Tuesday, the incoming payload structure shifted from 15 columns to 14 columns."
Here is how this approach compares to the standard "fire and forget" method often used in low-code implementations:
| Feature | Standard Automation | Metadata Sidecar |
|---|---|---|
| Schema Awareness | Implicit / Blind | Explicit / Logged |
| Drift Detection | Post-mortem only | Real-time visibility |
| Debugging Time | Hours (Trace logic) | Minutes (Check Ledger) |
| Analyst Trust | Low | High |
Why This Matters for Strategic Alignment
For a Data Analyst, "Data Janitorial Work"—cleaning up messes left by disparate systems—is a major pain point. By implementing the Metadata Sidecar Process, we are essentially automating the documentation of our own data pipelines.
This moves the conversation from "Why is the data wrong?" to "How can we leverage this data?"
We aren't just building automations to save time on tasks; we are building systems that produce reliable business intelligence. When we can prove to leadership that our automated processes are self-documenting and structurally sound, we validate the strategic value of the entire automation initiative.

