Architecting an Inbound Data Airlock for Standardized Sales Operations
The Endless Battle for CRM Hygiene
If you work in Sales Ops, you know the specific dread that comes when a Sales VP pings you about a duplicate account or a mangle job title in a critical report. It doesn’t matter if 99% of the data is accurate; that 1% error rate is enough to shatter trust in the entire system.
For years, my approach to data integrity was reactive. I built elaborate deduplication scenarios in Make and ran scheduled cleaning scripts after the data hit our CRM. It felt productive, but it was essentially bailing water out of a sinking boat. The mess was already inside the house.
Scaling operations forced a shift in perspective. We realized we couldn't rely on sales reps to be data entry clerks, nor could we trust every external enrichment tool to format data perfectly. The solution wasn't better cleaning tools; it was a better architecture. We needed a quarantine zone.
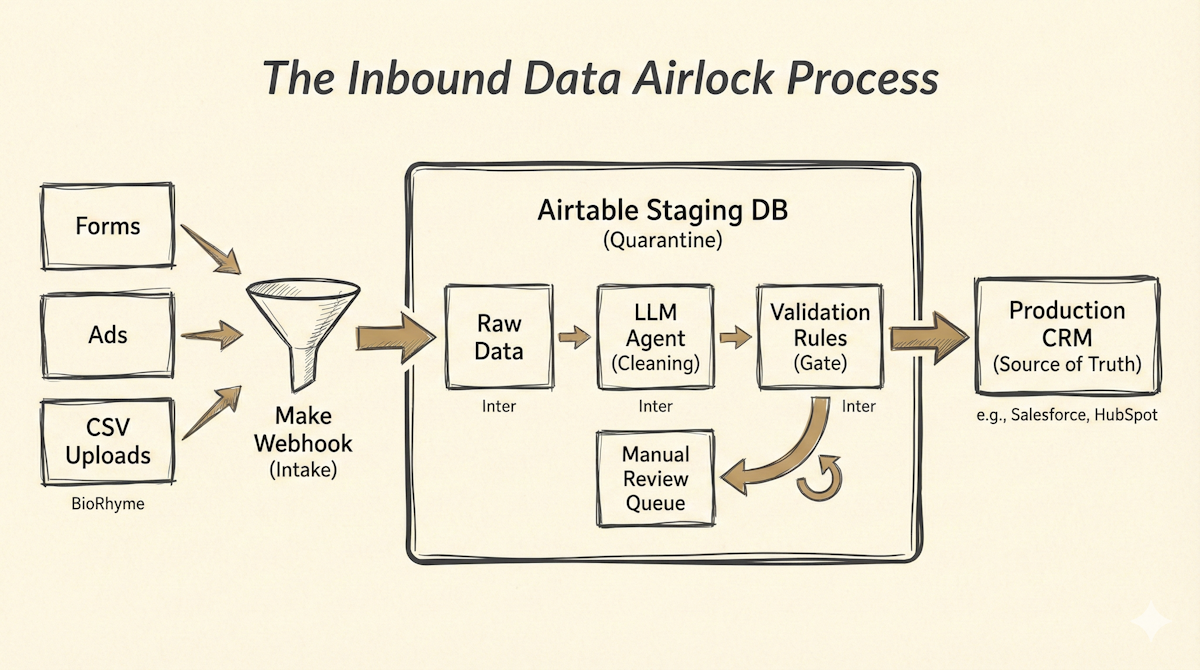
This blueprint outlines what we call The Inbound Data Airlock Process. It’s a defensive architecture designed to catch, standardize, and validate data before it ever touches your production CRM. It uses Airtable as a staging ground and Make to orchestrate the sanitization, leveraging an LLM to handle the messy human nuances of data entry.
The Core Philosophy: Staging Over Speed
The instinct in automation is speed—get the lead from the web form to the sales rep instantly. The Airlock Process deliberately introduces latency. It prioritizes standardized, high-fidelity data over real-time delivery of messy data.
By decoupling data intake from data storage (the CRM), we gain a buffer zone where we can apply rigorous rules without disrupting the sales team's workflow. If data fails validation, it gets stuck in the airlock for review rather than polluting the CRM.
The High-Level Architecture
This system relies on three core components working in a tight loop:
The Orchestrator (Make): Handles the movement of data between sources, the staging area, and the final destination.
The Staging Database (Airtable): Acts as the "source of truth" for inbound data processing and validation rules.
The Sanitization Agent (LLM via Make API): Standardizes unstructured inputs (like messy job titles or free-text industry descriptions).
Below is the breakdown of the five stages within this architecture.
Stage 1: The Unified Intake Layer (Make)
Data sources vary wildly—Typeform submissions, LinkedIn Lead Gen ads, manual CSV uploads from events, or enricher tools like Clearbit or Apollo. The mistake is building separate, direct paths from each source to your CRM.
Instead, point all inbound webhooks to a single Make scenario acting as a router. This scenario does very little processing; its only job is to map incoming payloads to a standardized JSON structure and create a record in the Airtable Staging Database. This ensures every piece of inbound data enters the system through the same front door.
Stage 2: The Staging "Quarantine" (Airtable)
Airtable is uniquely suited for this role because it combines database relational integrity with a spreadsheet-like interface that is accessible to Ops professionals.
Your Airtable base should mirror your CRM's core objects (Contacts, Companies). Crucially, it needs a Status field (e.g., New, Processing, Failed Validation, Ready for Sync, Synced).
When a record arrives, its status is New. This triggers the next stage.
Stage 3: Automated Sanitization (Make + LLM)
This is where the heavy lifting happens. A Make scenario watches for New records in Airtable. It takes the raw data and passes it through a series of cleaning modules.
While regex and standard formatting formulas handle things like phone number normalization (E.164 format) or email lowercase conversion, they fail on human nuances. This is where we inject an LLM node (OpenAI or Anthropic via Make).
We use a structured prompt to the LLM to normalize specific fields. For example, converting variations like "VP of Sales," "Vice President, Sales," and "Sales VP" into a standardized picklist value: "Vice President - Sales." We also ask the LLM to parse unstructured text blocks for missing information or flag obvious junk entries (e.g., "asdf" in the name field).
The cleaned data is then updated back into the Airtable record, and the status moves to Processing.
Stage 4: The Validation Gate (Airtable Views)
Now the data is clean, but is it valid relative to your existing database? Back in Airtable, we use sophisticated formulas and lookups (often leveraging synced tables from the actual CRM) to check for duplicates based on email domains, company names, or fuzzy matching logic.
Airtable views act as the gates. A record only enters the "Ready for Sync" view if it passes all formulaic validation checks (e.g., Is Duplicate = FALSE, Required Fields Present = TRUE, Email Syntax Valid = TRUE).
Records that fail are filtered into an "Exception Queue" view. An Ops analyst can review this queue once a week, manually fix the data, or reject the lead. The automation doesn't break; it just pauses problem records.
Stage 5: The Production Sync (Make)
The final step is the simplest. A Make scenario watches the "Ready for Sync" view in Airtable. It takes the fully validated, standardized, and deduplicated packet of data and upserts it into your CRM (HubSpot, Salesforce, etc.).
Because the data has already survived the airlock, the CRM API calls rarely fail. Once successfully synced, Make updates the Airtable record status to Synced and logs the new CRM ID for future reference.
The Non-Obvious Benefit: Regaining Trust
Implementing The Inbound Data Airlock Process requires an upfront investment in architecture and a willingness to accept a slight delay in lead routing. However, the payoff isn't just cleaner reporting.
The real benefit is cultural. When the sales team stops seeing duplicates and standardized job titles appear magically in their accounts, they stop maintaining their own "shadow ops" spreadsheets. They begin to trust the CRM as the actual source of truth. And for those of us in Sales Ops, that trust is the fuel that lets us move from constant firefighting to strategic scaling.
References

