Teardown: Modernizing Reconciliation With The Vector-Based Matching Process
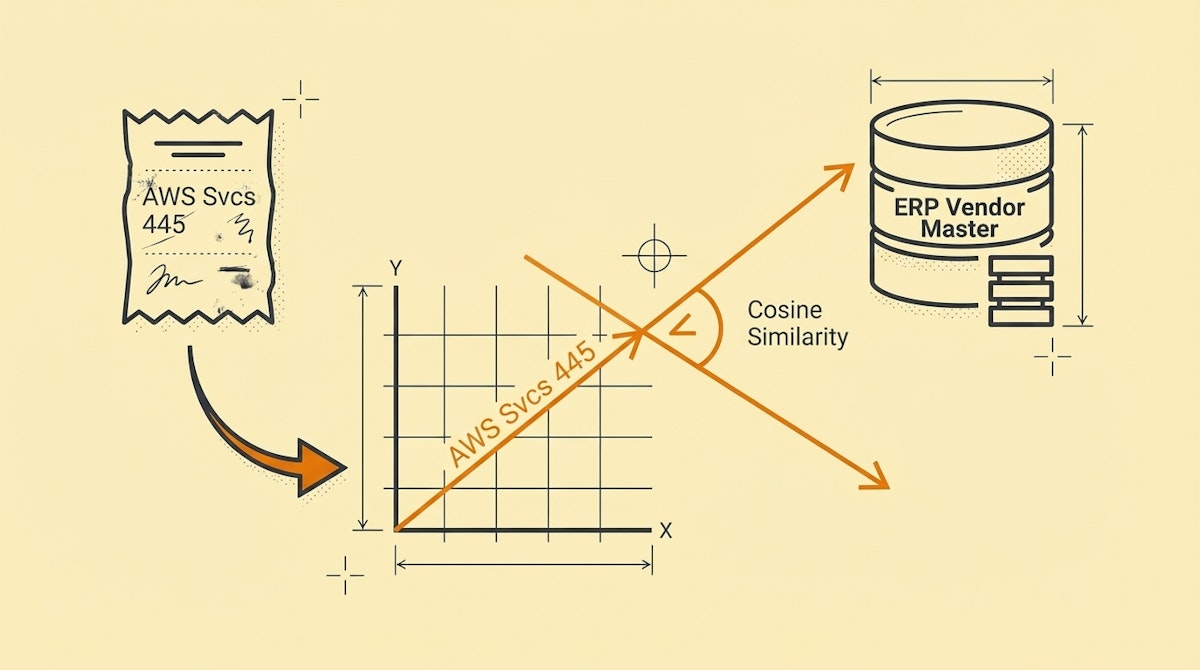
The monthly reconciliation process is often the single biggest bottleneck in finance operations. It usually boils down to a messy data problem: the string of text on a bank statement rarely matches the string of text in the ERP or the invoice received.
For years, Financial Controllers have relied on "Fuzzy Matching" algorithms (like Levenshtein distance) to bridge this gap. If the text is 80% similar, the system suggests a match. However, this approach is fragile. It fails when "Amazon Web Services" appears as "AWS" on the bank feed—statistically, those strings share almost no characters, yet they are the same entity.
To solve this without manual review, we can look at how modern fintech infrastructure (like Ramp or Brex) handles transaction enrichment. They utilize Vector Embeddings. By converting text into numerical coordinates, we can perform "Semantic Entity Resolution," matching records based on conceptual proximity rather than just character overlap.
This Deep Dive explores how to implement a Vector-Based Matching Process using low-code tools to automate complex reconciliation scenarios.
The Concept: From Fuzzy Logic to Vector Space
Traditional automation fails at reconciliation because it relies on exact or near-exact syntax. If a vendor changes their billing descriptor, the automation breaks.
Vector embeddings work differently. They transform text into a list of floating-point numbers (a vector) representing the semantic meaning of that text. When we plot these vectors in a multi-dimensional space, "AWS" and "Amazon Web Services" land very close to each other, allowing us to calculate a "Cosine Similarity" score.
Here is how the approaches compare regarding operational overhead:
| Method | Mechanism | Strengths | Weaknesses |
|---|---|---|---|
| Exact Match | 1:1 Text Identity | 100% Accuracy | Brittle; fails on typos |
| Fuzzy Logic | Character Overlap | Handles typos | Fails on abbreviations |
| Vector Matching | Semantic Proximity | Handles context/alias | Requires embedding API |
The Vector-Based Matching Process
To implement this using tools like Make or n8n, we shift from a conditional logic workflow (If X then Y) to a mathematical workflow.
Phase 1: The Reference Index (The "Golden" Data)
First, we must establish what we are matching against. Usually, this is your Vendor Master list in the ERP (e.g., NetSuite, Xero, QuickBooks).
- Extract Vendor Names: Pull the clean list of active vendors.
- Generate Embeddings: Send these names to an embedding model (like OpenAI's
text-embedding-3-small). - Store Vectors: Store the resulting vector array in a database capable of vector operations (Supabase with pgvector, Pinecone, or even a local JSON file for small lists).
Phase 2: Inbound Transaction Processing
When a new bank line item arrives (e.g., via a Plaid webhook or CSV parser):
- Clean the String: Remove standard banking noise (e.g., "POS DEBIT", "ACH TRANSFER").
- Vectorize the Input: Send the cleaned bank description to the same embedding model used in Phase 1.
- Query the Index: Perform a "Nearest Neighbor" search against your Reference Index.
Phase 3: The Confidence Threshold
The output of this search is not a simple "Yes/No." It is a Similarity Score (usually between 0 and 1). This allows us to build a tiered governance system:
- Score > 0.90: High confidence. Automatically reconcile or create the Draft Bill.
- Score 0.80 - 0.89: Moderate confidence. Flag for human review but pre-fill the suggested vendor.
- Score < 0.80: Low confidence. Treat as a new vendor or anomaly.
Implementation Nuances
The "Dirty Data" Advantage
One significant advantage I have observed with this approach is its ability to learn from "Dirty Data." If you have historical data where a human manually matched "AMZN MKTPLC" to "Amazon," you can embed the dirty version and link it to the clean ID.
This creates an automated feedback loop: every time a human manually corrects a match, that specific bank string can be vectorized and added to the index, ensuring the model never makes the same mistake twice.
Cost and Latency
Financial Controllers worry about cost. The text-embedding-3-small model is extremely efficient. Processing thousands of transaction lines typically costs pennies. The latency is minimal, making it viable for near real-time dashboards.
Conclusion
The goal of the Vector-Based Matching Process isn't just to save a few seconds on data entry. It is to increase trust in the financial close. by moving away from rigid rules that require constant maintenance (e.g., maintaining a list of 50 different ways a vendor might appear), we build a system that is resilient to variance.
This shift allows the finance team to stop acting as data janitors and start focusing on analysis and strategy.
References
- Stripe: Smart Retries and Machine Learning optimization
- OpenAI: Embeddings API Documentation
- Pinecone: What is Vector Similarity Search?

