Teardown: Ramp’s Expense Compliance Through The Confidence-Based Routing Process
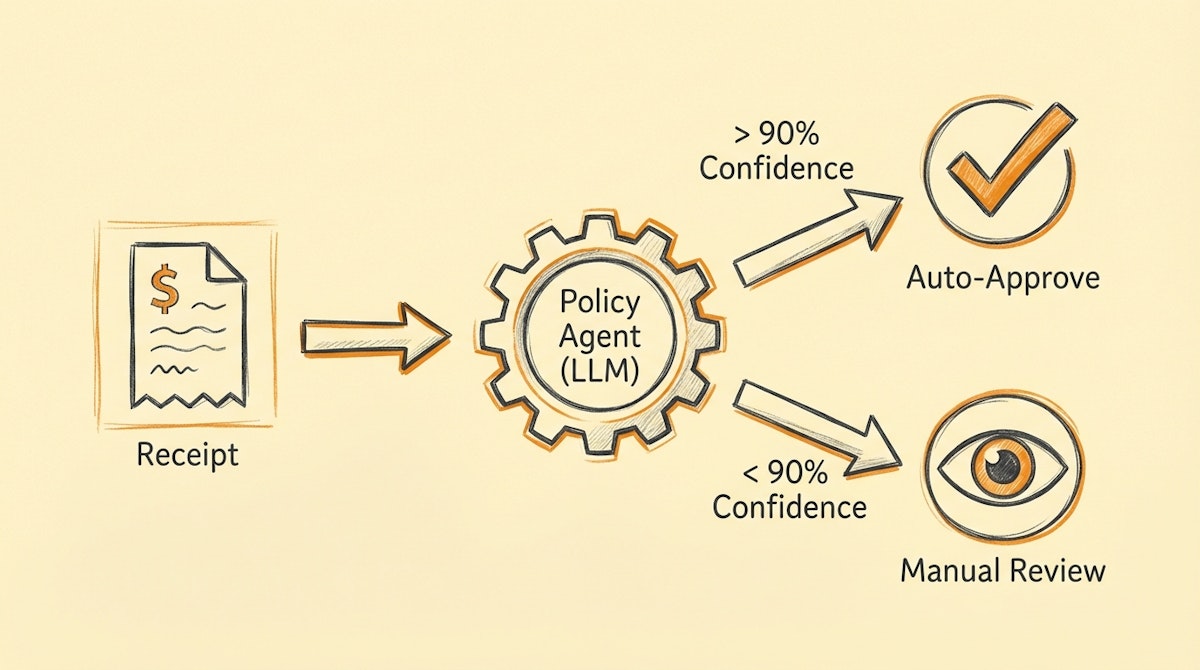
Table of Contents
- The Analysis: Policy Enforcement at Scale
- The Blueprint: The Confidence-Based Routing Process
- Phase 1: Ingestion and Semantic Extraction
- Phase 2: The Policy Evaluation Agent
- Phase 3: The Threshold Guardrail
- Comparison: Static Rules vs. Semantic Evaluation
- Conclusion
One of the most tedious aspects of a Financial Controller’s role is the monthly expense reconciliation ritual. You are often forced to act as the "bad cop," manually verifying if a $40 lunch fits within the travel policy or if a software subscription was actually pre-approved.
The traditional approach relies on rigid, rule-based automation (e.g., "If amount > $500, require approval"). However, this binary logic often fails to capture context. It flags legitimate urgent expenses or, worse, auto-approves low-cost purchases that violate the nature of the company policy (like purchasing alcohol or unauthorized software).
In this teardown, I want to look at how modern spend management platforms like Ramp have approached this challenge. They have shifted from static rules to dynamic policy enforcement. By observing their feature set, we can reverse-engineer a similar logic using tools like Make, OpenAI, and Airtable to build what I call the Confidence-Based Routing Process.
The Analysis: Policy Enforcement at Scale
Ramp’s core value proposition isn't just issuing corporate cards; it is the promise of "controlling spend before it happens." They utilize an engine that checks transactions against complex, natural-language policies in real-time.
Instead of just checking the amount, the system evaluates the context. Is this vendor compatible with the department’s budget? Is the receipt matching the transaction data?
For a DIY implementation, we cannot easily replicate the "real-time blocking" of a card swipe without banking infrastructure. However, we can replicate the intelligent auditing workflow that happens immediately after the transaction, moving the Controller from a data-entry role to a supervisory role.
The Blueprint: The Confidence-Based Routing Process
This process introduces a layer of probabilistic logic between the expense submission and the accounting software (like QuickBooks or Xero). Instead of a binary "Pass/Fail," we introduce a "Confidence Score."
Here is how I structure this workflow:
Phase 1: Ingestion and Semantic Extraction
First, unstructured data (PDF receipts, email forwards, or Slack commands) arrives in the automation platform (e.g., Make or n8n).
Before checking the policy, we need to normalize the data. An LLM (like GPT-4o) extracts key entities: Vendor, Date, Total Amount, Currency, and Line Items.
Crucially, we also ask the model to generate a "Context Summary"—a one-sentence description of what was purchased and arguably why, based on the visual evidence of the receipt.
The Policy Evaluation Agent
This is where the governance logic lives. We feed the extracted data and the Context Summary into a second LLM prompt. This prompt also contains the company’s Expense Policy as plain text context.
The prompt instructions are specific:
"Act as a strict Financial Controller. Compare this expense against the provided policy. Output a JSON object containing: a boolean 'is_compliant', a short 'reasoning', and a 'confidence_score' between 0.0 and 1.0."
If the policy says "No alcohol," and the receipt shows a bottle of wine, the model identifies the breach semantically, even if the vendor category is generic like "Dining."
Phase 3: The Threshold Guardrail
We do not blindly trust the AI. This is where the Confidence-Based Routing comes in. We set a governance threshold, typically at 0.9 (90%).
- High Confidence (Score > 0.9): If the AI is sure the expense is compliant, the automation can draft the expense in the ERP or even auto-approve it if the amount is low.
- Low Confidence / Violation (Score < 0.9 or Compliant = False): The automation routes this to a "Manual Review" queue (Airtable or a Slack channel).
The Controller only sees the exceptions or the ambiguous cases, drastically reducing the volume of manual review.
Comparison: Static Rules vs. Semantic Evaluation
To understand why this shift matters for governance, look at the structural differences between legacy rule sets and this semantic approach.
| Feature | Static Rules (Legacy) | Confidence Routing (AI) |
|---|---|---|
| Trigger Logic | If Amount > X | If Policy Violated |
| Context Awareness | None (Blind) | High (Reads Receipt) |
| Risk of Error | False Negatives | Hallucination (Mitigated by Score) |
| Maintenance | Complex RegEx | Update Text Policy |
Conclusion
The goal of the Confidence-Based Routing Process is not to remove human oversight, but to make it scalable. By letting the system handle the clear-cut cases (both approvals and obvious rejections), you free up mental energy to focus on the edge cases that actually require a Financial Controller's judgment.
Start small. I recommend running this process in "Shadow Mode" first—where the AI scores expenses but doesn't take action—so you can audit its decisions against your own for a few weeks before turning on auto-approvals.
References
- Ramp Intelligence Overview
- Make.com JSON Handling Documentation
- OpenAI Function Calling for Structured Outputs
Related posts

