Teardown: Netflix’s Content Personalization & The Dynamic Asset Scoring Process
Netflix isn't just a streaming service; it is arguably one of the most sophisticated data processing engines in existence. As growth engineers, we often look at their ability to serve the right content to the right user at the right time with envy.
One specific mechanism stands out: Artwork Personalization.
Netflix doesn’t serve a single static image for Stranger Things. If you watch romantic comedies, you might see an image of Hopper and Joyce sharing a moment. If you watch horror, you see a darker, scarier frame. They don't just guess; they use online machine learning (specifically contextual bandits) to maximize the probability of a play.
Most of us don't have the engineering resources to deploy custom contextual bandit algorithms. However, we can approximate this logic using modern low-code tools and LLMs. By deconstructing their approach, we can build a Dynamic Asset Scoring Process that ensures data integrity between marketing assets and user segments.
The Teardown: How Netflix Does It
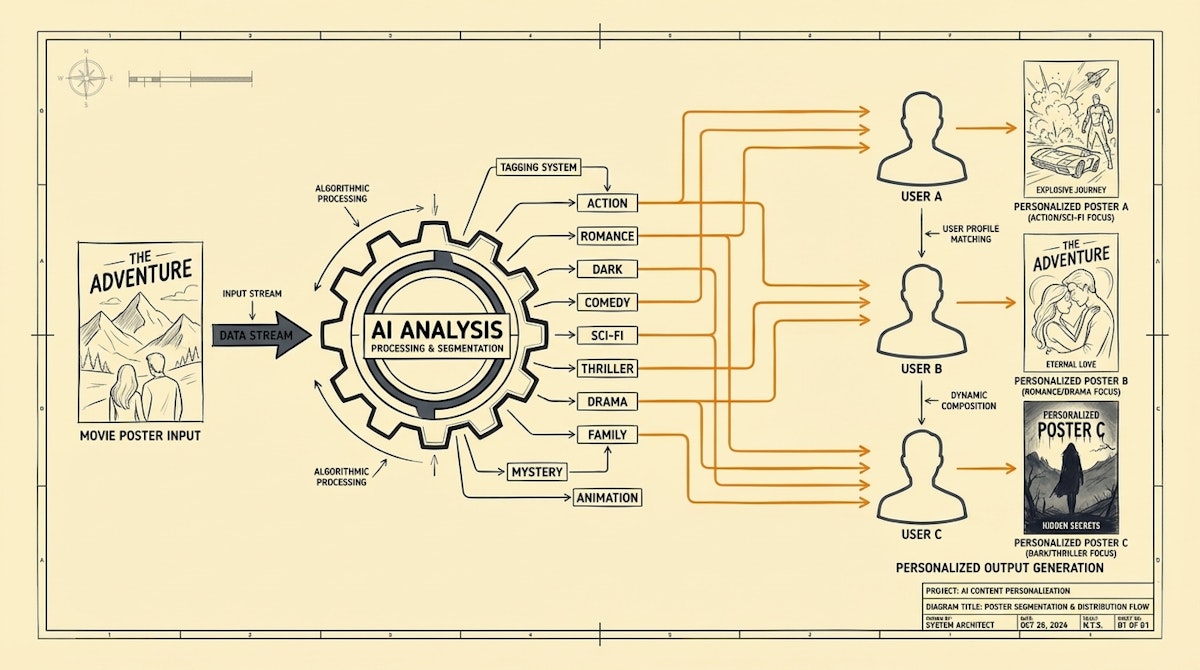
At a high level, Netflix’s engine relies on structured metadata. They treat every piece of artwork not as a blob of pixels, but as a collection of data points (tags, colors, emotions, characters).
Simultaneously, they maintain a rigorous "member profile" composed of similar data points derived from viewing history. The "magic" is simply a high-velocity matching process between the Asset Metadata and the User Metadata.
For the average growth stack, the failure point is usually the Asset Metadata. We have plenty of user data (in Segment, Mixpanel, or HubSpot), but our creative assets are often "dumb" files sitting in a DAM or Google Drive with no structured data attached.
The Solution: The Dynamic Asset Scoring Process
To replicate this personalization strategy without a dedicated ML team, we need to solve the data integrity gap. We need a system that standardizes creative assets into data that can be programmatically matched against user preferences.
This process consists of three distinct stages:
- Semantic Ingestion (Turning creative into data)
- Attribute Mapping (Standardizing the language between assets and users)
- The Scoring Logic (The decision engine)
Phase 1: Semantic Ingestion
Before we can personalize, we need to know what we are serving. Manual tagging is prone to human error and inconsistency (drift). The scalable approach is to use a Multimodal LLM (like GPT-4o or Claude 3.5 Sonnet) to analyze incoming creative assets.
In this workflow, every time a new creative asset (banner, email header, ad creative) is uploaded to a staging base (like Airtable or a DAM), a webhook triggers an automation in Make or n8n.
The automation sends the image to the Vision model with a strict system prompt to extract structured JSON data: dominant colors, sentiment, text density, and thematic tags.
Phase 2: Attribute Mapping
The challenge in data integrity is ensuring that the tags generated for the image match the fields we track in our CRM or CDP. If the LLM tags an image as "Joyful" but our CRM tracks users who like "Upbeat" content, the match fails.
We solve this with a Normalization Step. The automation references a "Dictionary" database—a single source of truth for allowed tags. If the LLM produces a new tag, it must be mapped to the closest existing allowable attribute or flagged for review. This ensures the "fuel" for our automation remains clean.
Phase 3: The Scoring Logic
This is where the "personalization" happens. Instead of complex ML, we use a weighted scoring script.
When a user qualifies for a campaign (trigger), the workflow pulls their top 3 attributes (e.g., Preference: Technical, Tone: Direct, Format: Text-Heavy). It then queries the asset database.
For each available asset variant, the script calculates a score based on how many metadata tags match the user's attributes. The asset with the highest score is injected into the email or landing page dynamically.
Comparing Approaches
The shift here is moving from static A/B testing (winner takes all) to dynamic allocation (best fit for the individual).
| Feature | Traditional A/B Testing | Dynamic Asset Scoring |
|---|---|---|
| Goal | Find one winner | Match context to user |
| Data Requirement | Traffic Volume | Metadata Integrity |
| Asset Lifespan | Short (until fatigue) | Long (re-routed to new segments) |
Implementation Requirements
To build this, you generally need:
- Orchestration: n8n or Make to handle the logic flow.
- Intelligence: OpenAI API (Vision) for analyzing the assets.
- Database: Airtable or Postgres to store the Asset Metadata and the Dictionary.
- Delivery: A flexible frontend or ESP (like Customer.io or Braze) that accepts liquid templating or dynamic content blocks.
Why Data Integrity Matters Here
The reason most personalization efforts fail isn't the lack of algorithms; it's the lack of standardized data. If your creative team labels a file "v2_final_blue" and your data team tracks "User_Segment_Enterprise", there is no bridge.
The Dynamic Asset Scoring Process forces a conversation about standardization. By treating creative assets as structured data records, we unlock the ability to automate relevance. We might not reach Netflix's level of real-time inference immediately, but we can certainly move beyond the "one size fits all" blast.

