Mistake: Hardcoding Cleaning Rules. Solution: The Semantic Normalization Process (Ref: Plaid)
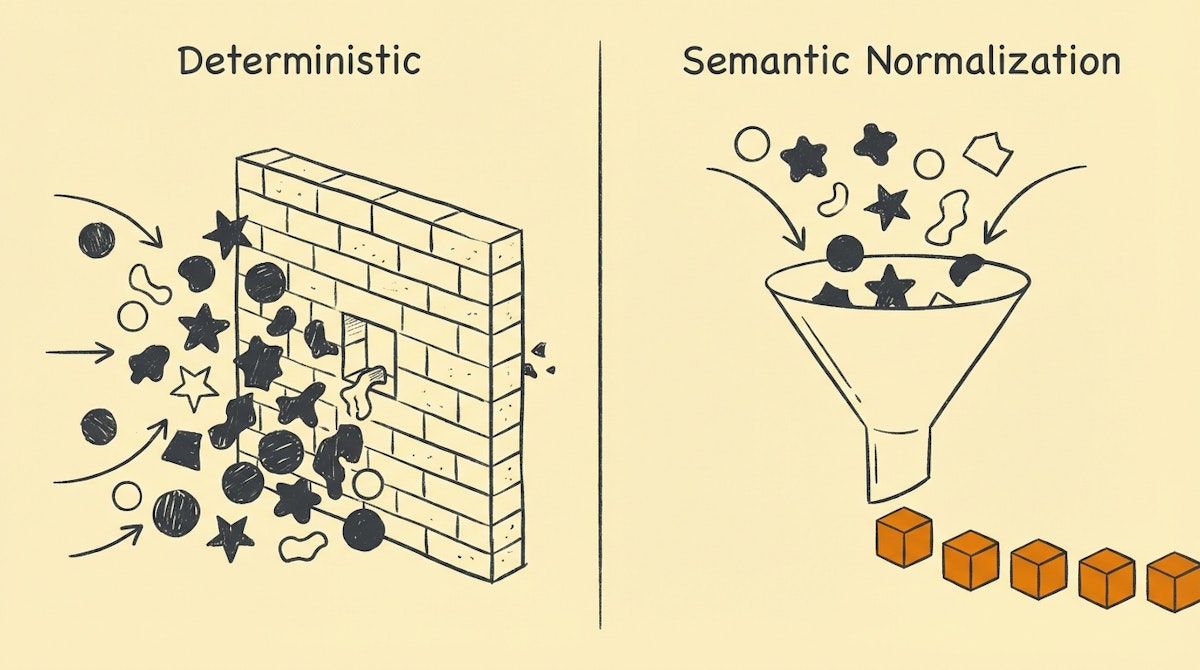
We have all stared at that one SQL query or Python script—the one with the CASE WHEN statement that spans 200 lines.
It usually looks like this:
- If input is "Cal.", change to "California"
- If input is "Cali", change to "California"
- If input is "CA", change to "California"
As Data Analysts, we pride ourselves on precision. We want our dashboards to be pixel-perfect and our foreign keys to match exactly. But often, in our quest for order, we commit a cardinal sin of automation: we try to hardcode logic for human unpredictability.
I have observed this pattern in countless Make scenarios and n8n workflows. We build rigid filters and complex Regex formulas to catch bad data at the door. But the moment a sales rep enters a new variation we hadn't anticipated, the pipeline breaks, the dashboard goes blank, and we are back to doing "data janitor" work on the weekend.
There is a more resilient way to handle this. It’s a strategy used by fintech giants like Plaid to turn messy bank transaction strings into clean merchant names, and we can replicate it using modern LLMs. It is called the Semantic Normalization Process.
The Mistake: The "Infinite Regex" Trap
The mistake isn't validation itself; it's the method of validation.
When we rely on deterministic rules (like Regex or exact lookups) to clean user-generated content, we are fighting a losing battle. We are assuming we can predict every possible way a human can misspell a company name, format a phone number, or abbreviate a job title.
This approach creates brittle systems. Every time the inputs drift slightly from your hardcoded expectations, you have to manually update the automation logic. You become the bottleneck.
The Solution: The Semantic Normalization Process
Instead of rejecting data that doesn't fit, or writing endless rules to force it to fit, we use a probabilistic layer—specifically an LLM—to coerce the data into a standard format before it hits your database.
This is essentially what Plaid does. When you buy coffee, your bank statement might say "STARBUCKS #00432 NY". Plaid doesn't have a Regex rule for store #00432. They use models to recognize the entity "Starbucks" within the noise and normalize it to a clean Merchant ID.
Here is how you can build this "fuzziness" into your own ETL pipelines using tools like Make or n8n.
Phase 1: Define the "Golden Record" (Enums)
Before you can normalize data, you need a target. You cannot just ask an AI to "clean this." You must provide the strict schema you want as the output.
Create a reference table (in Airtable or a simple JSON array) that lists the valid values.
- Bad Target: "Fix the job titles."
- Good Target: "Map the input to one of these 5 values: [Executive, Manager, Individual Contributor, Student, Other]."
Phase 2: The Semantic Router Node
In your automation tool, insert an LLM node (GPT-4o mini or Claude 3 Haiku are perfect here—fast and cheap) between the trigger (e.g., Typeform, HubSpot) and the destination (e.g., Snowflake, Postgres).
The Prompt Structure:
"You are a data normalization engine.
Input: {User_Input_Variable}
Target Schema: [List_Of_Valid_Values]Task: Map the input to the closest matching value in the Target Schema.
Constraint: Output ONLY the matching value. If no logical match exists, output 'Unclassified'. Do not explain your reasoning."
This turns the LLM into a fuzzy matching engine. It handles the complexity of human language (typos, slang, abbreviations) so your code doesn't have to.
Phase 3: The Confidence Guardrail
For critical financial data, you might be worried about hallucinations. This is where you add a confidence score.
Ask the LLM to return a JSON object:
{
"normalized_value": "Manager",
"confidence_score": 0.95
}
Then, add a Router in your workflow:
- If Confidence > 0.90: Proceed to auto-update the database.
- If Confidence < 0.90: Send to a Slack channel for manual review (Human-in-the-Loop).
Comparing Approaches
Here is why shifting from Regex to Semantic Normalization saves you technical debt:
| Feature | Hardcoded Rules (Regex) | Semantic Normalization (LLM) |
|---|---|---|
| Maintenance Effort | High (Constant updates) | Low (Set & Forget) |
| Edge Case Handling | Fails (Breaks pipeline) | Adapts (Contextual guess) |
| Setup Time | Slow (Writing logic) | Fast (Prompting only) |
Conclusion
Automation shouldn't be fragile. By moving the complexity of data cleaning from rigid code to a semantic layer, you effectively future-proof your pipelines against the chaos of the real world.
You stop being the "Data Janitor" writing Regex on Friday nights and start being the architect of a self-healing data ecosystem. That is where the real value of the Data Analyst role lies: ensuring connectivity and integrity without constant manual intervention.

