Forecast: Shifting From Strict Validation To Schema-On-Read Automation
The Burden of Being the "Form Police"
If you manage internal operations, you likely spend a disproportionate amount of time enforcing data quality. You build forms in Airtable or Typeform, set up strict validation rules (regex patterns, mandatory fields, dropdowns), and then chase down team members who inevitably bypass them or find creative ways to input bad data.
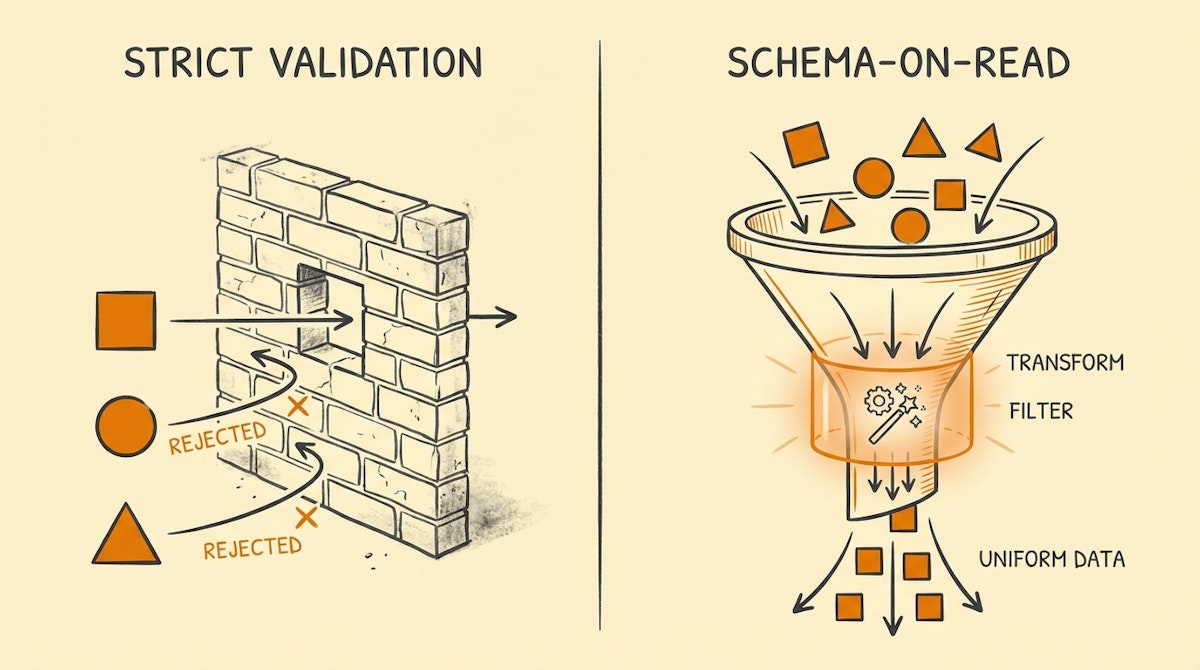
The prevailing strategy for the last decade has been Schema-on-Write. This means we define the structure of the data before it enters the system. If the input doesn't match the structure, the automation fails (or the form rejects the submission). This places the burden of data quality entirely on the human user, creating friction and resistance to adoption.
However, I am observing a fundamental shift in how we approach this, driven by the plummeting cost of LLM tokens and the rise of JSON-mode outputs in models like GPT-4o and Claude 3.5 Sonnet.
Over the next 6-12 months, I predict a transition in operational automation from Strict Validation to Schema-on-Read Automation. Instead of forcing humans to structure data for machines, we will use automation layers to structure data after it has been received but before it hits the database.
The Concept: Schema-on-Read for Operations
The concept of Schema-on-Read isn't new; it is a foundational principle of Big Data architectures (like Hadoop or data lakes used by Databricks). In that context, raw data is dumped into a lake and only structured when it is queried.
Applying this to internal operations (using tools like Make or n8n) changes the workflow dynamic entirely. Rather than building rigid front-end validators, we build a "repair layer" in the middle of the automation.
Why this shift is happening now
Two specific technological constraints have relaxed, making this viable:
- Latency: LLMs are now fast enough to process a text payload and return a JSON object in under 2 seconds, making them usable in synchronous workflows.
- Reliability: With features like OpenAI's
response_format: { "type": "json_object" }, we can now guarantee that the output of an LLM is machine-readable code, not conversational text.
The New Architecture: The Self-Healing Data Pipeline
In this forecasted model, the automation flow changes from a linear pass/fail gate to a filtering funnel.
Here is how I see this utilizing current low-code stacks:
- The Permissive Input: The entry point (Slack, Email, loose Form) accepts almost any format. A user can type "I need a vacation next Friday" or "Booking off 12th Jan." The system does not reject it.
- The LLM Normalization Node: This is the new standard component. It takes the unstructured input and attempts to map it to the required database schema (e.g.,
{ "start_date": "YYYY-MM-DD", "type": "PTO" }). - The Confidence Router: Instead of boolean success/failure, the system assigns a confidence score. If the LLM is 99% sure, it proceeds. If it is ambiguous, it routes to a human-in-the-loop workflow for verification (e.g., a Slack button that asks, "Did you mean January 12th?").
| Feature | Strict Validation (Current) | Schema-on-Read (Forecast) |
|---|---|---|
| User Experience | High Friction (Rejects errors) | Low Friction (Auto-correction) |
| Maintenance | Complex Regex/Logic | Prompt Engineering |
| Data Loss | High (Rejected inputs lost) | Low (Raw data preserved) |
Strategic Implications for Ops Managers
For the Internal Ops Manager, this shift changes the definition of "efficiency."
1. Reduced Training Overhead
Currently, a significant portion of onboarding is teaching employees how to use internal tools correctly (e.g., "You must select 'Hardware Issue' in the Jira dropdown, not 'IT Support'"). With Schema-on-Read, the system infers the category based on the ticket description. The focus shifts from training humans to conform to software, to training software to understand humans.
2. The Rise of "Shadow Data"
There is a risk. By accepting messy data, you potentially accumulate a backlog of unparsable inputs (the "sediment" at the bottom of the data lake). I anticipate a new operational necessity: the weekly "Exception Review," where an admin reviews the 2-5% of data the LLM couldn't structure.
3. Cost Management
While developer time is saved on building complex validation logic, operational costs (OpEx) will rise slightly due to API costs for the LLM processing. However, given the current price trajectory of inputs (like GPT-4o-mini), this cost is becoming negligible compared to the cost of an employee spending 10 minutes re-submitting a rejected form.
Preparing for the Shift
To prepare for this transition, I suggest auditing your current "Fail Points." Look at your automation logs in Make or Zapier. Where are the errors occurring? If the majority of errors are "Validation Failed" or "Missing Field," you are a prime candidate for testing a Schema-on-Read workflow.
Start small. Take a simple process—like an internal IT ticketing system or expense submission—and remove the strict validation fields. Replace them with a single text box and an LLM parser backend. Measure if user satisfaction goes up and if the data quality remains acceptable.
The future of internal operations isn't about perfect data entry; it's about perfect data interpretation.
References
- Databricks: What is a Data Lake? (Concept of Schema-on-Read)
- OpenAI Documentation: JSON Mode
- Make Community Forum (Discussions on Error Handling)

