Teardown: Airbnb’s Data Quality & The Semantic Extraction Process
As data professionals, we are often caught in a zero-sum game between Data Integrity and User Adoption.
Here is the dilemma: To get clean data for our dashboards, we build rigid input forms with mandatory dropdowns, regex validation, and conditional logic. We force users to structure the data for us.
The result? Users hate the friction. They select the first option in the dropdown just to bypass the field, or they stop filling out the form entirely. We get "clean" structure, but garbage content.
On the other hand, if we prioritize user experience and allow free-text input, adoption goes up, but we end up with a data swamp that requires hours of manual janitorial work to standardize.
Airbnb faced this exact challenge at a massive scale. To categorize millions of listings without forcing hosts to fill out a 500-question survey, they shifted the burden of structure from the user to the machine.
This article breaks down how we can replicate this approach using modern automation tools (Make, n8n) and LLMs to build the Semantic Extraction Process.
The Teardown: Airbnb’s Amenity Detection
Airbnb needs structured data to power its filters (e.g., "Has Coffee Maker" or "Ocean View"). Initially, one might think the solution is a massive checklist for the host.
However, Airbnb realized that hosts describe their homes naturally in the description text or through captions. Instead of forcing a rigid schema on the host, Airbnb utilizes deep learning and natural language processing to infer attributes from unstructured data.
When a host writes "Enjoy a morning brew on the balcony overlooking the pacific," Airbnb’s backend models detect:
amenity_coffee_maker: Trueview_type: Oceanoutdoor_space: Balcony
They decouple the Input Experience (creative, unstructured) from the Data Storage (rigid, structured). For the Data Analyst, this is the holy grail: low friction for the human source, high integrity for the BI tool.
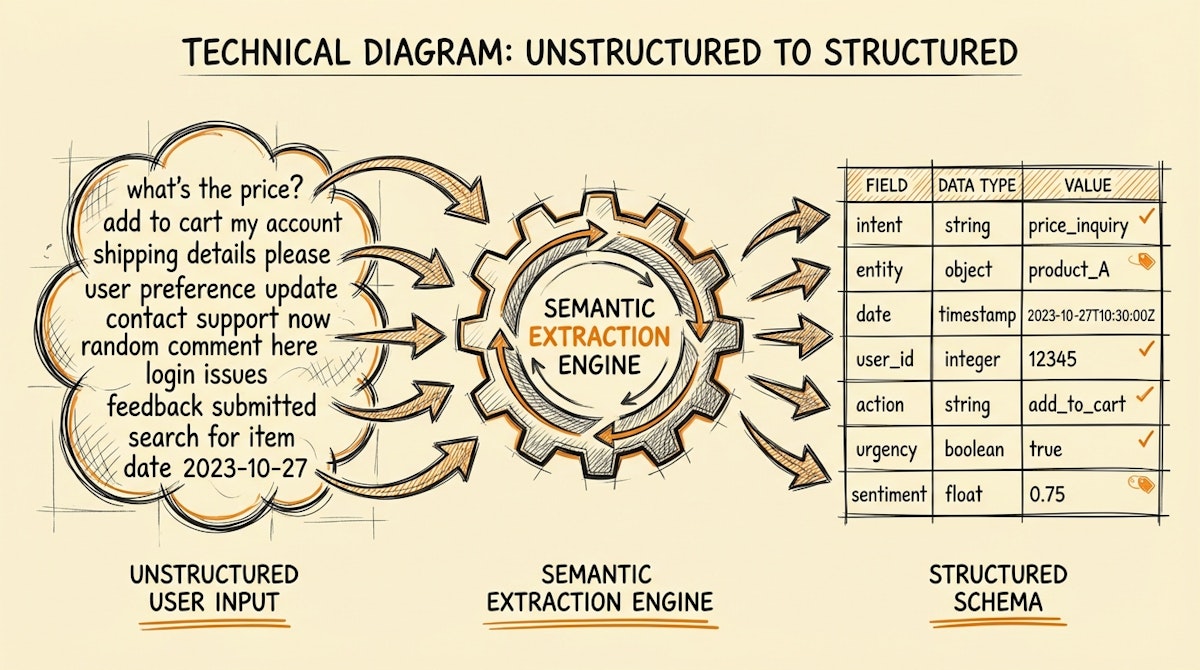
The Blueprint: The Semantic Extraction Process
We can implement a simplified version of this architecture to solve internal data collection problems (e.g., Sales CRM notes, Customer Support tickets, or Vendor Onboarding).
The goal is to allow the user to provide data in the format most natural to them (text, email, voice), and use an automation layer to map it to your database schema.
| Dimension | Rigid Validation (Old Way) | Semantic Extraction (New Way) |
|---|---|---|
| User Experience | High Friction (Dropdowns) | Frictionless (Natural Text) |
| Data Quality | False Precision (User error) | High Accuracy (Contextual) |
| Maintenance | High (Updating Form Logic) | Low (Updating System Prompt) |
Step 1: The Unstructured Ingest
Instead of a complex Typeform with conditional branching, provide a simple interface. If you are collecting sales data, it might just be a text area asking: "Tell us about the lead's budget, timeline, and main pain points."
The user writes a paragraph. They feel heard, not interrogated.
Step 2: The LLM Schema Mapper
This is where the "Janitorial Work" is automated. In your orchestration tool (Make or n8n), pass the raw text into an LLM node (GPT-4o or Claude 3.5 Sonnet).
You must provide the LLM with your Target Data Schema. Do not ask it to "summarize." Ask it to "extract and format."
Example System Prompt:
"You are a Data Transformation Engine. Analyze the following unstructured text. Extract values for the following JSON keys: 'budget_amount' (number), 'timeline_month' (string), 'pain_points' (array of strings). If a value is missing, return null. Do not hallucinate."
Step 3: The Validation Gate
LLMs are probabilistic, so we cannot blindly trust the output for mission-critical data. We need a guardrail.
Implement a Confidence Check or a Human-in-the-Loop step for ambiguous data.
- Deterministic Validation: If the LLM returns a 'budget_amount' that is not a number, flag it.
- Semantic Validation: If the text says "budget is tight" but the LLM extracts "$0", route this to a human for review via Slack or Microsoft Teams.
Step 4: The Silent Update
Finally, update your system of record (Postgres, Snowflake, Airtable). Ideally, keep a "Raw Input" field and a "Structured Data" field. This allows you (the Data Analyst) to audit the transformation later if you suspect data drift.
Why This Matters
For a Data Analyst, the instinct is often to lock down inputs to ensure quality. But in an organization, usage is a prerequisite for data. If the sales team refuses to use the CRM because the forms are too long, you have no data to analyze.
By adopting the Semantic Extraction Process, you position yourself not as the "Data Police" forcing people to click buttons, but as a strategic partner who makes data entry invisible. You get your structured rows and columns; they get to write like humans.
References
- Airbnb Engineering: Categorizing Listing Photos at Airbnb - https://medium.com/airbnb-engineering/categorizing-listing-photos-at-airbnb-f9483f028244
- Airbnb Engineering: Amenity Detection - https://medium.com/airbnb-engineering/amenity-detection-and-photo-grouping-at-airbnb-3e604a29a071
- Concept: Extracting Structured Data from Text (OpenAI) - https://platform.openai.com/docs/guides/structured-outputs

