Forecasting The Shift From Rigid Schemas To Adaptive Normalization (Snowflake-Inspired)
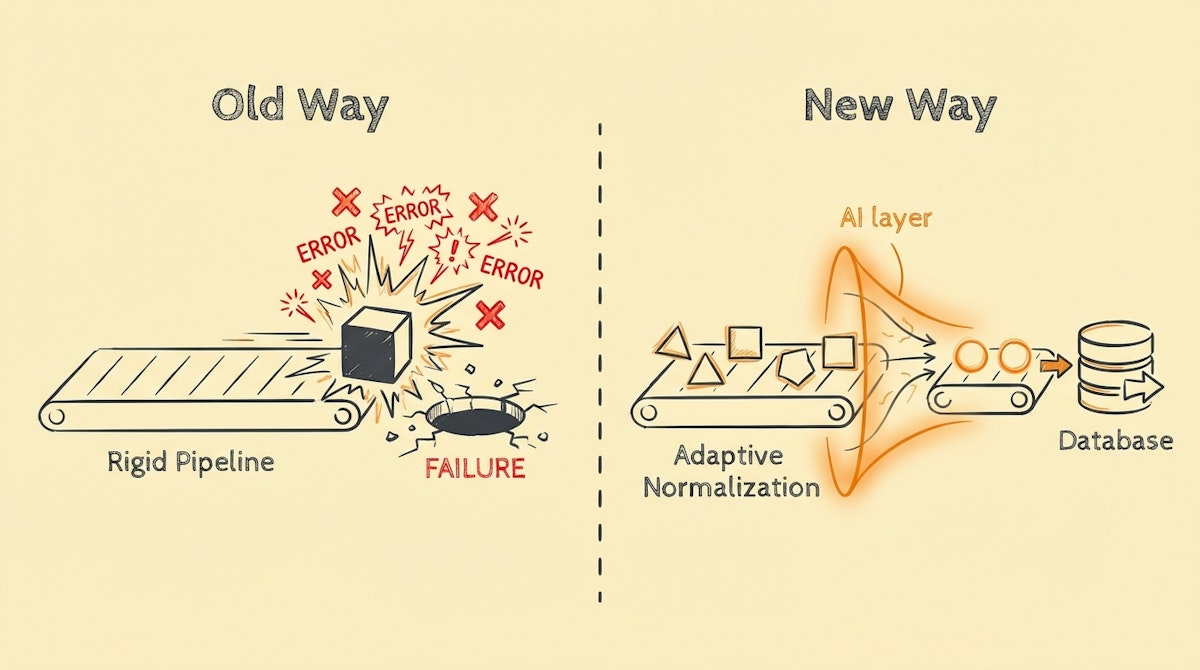
The most fragile part of any Data Analyst’s workflow isn't the analysis itself; it is the ingestion pipeline. We have all faced the specific frustration of a dashboard going flatline on a Monday morning because a marketing manager renamed a column in a Google Sheet, or a SaaS API deprecated a field without warning.
Traditionally, our response has been Rigid Schema Enforcement. We build automations that expect data in an exact format. If the input deviates by even a single character, the pipeline fails, an error is thrown, and we spend hours debugging just to restore the flow. This is the "Fragility Trap."
However, looking at the trajectory of LLM token costs and latency (specifically with models like GPT-4o Mini or Claude 3 Haiku), I forecast a fundamental shift in automation strategy over the next 6 to 12 months. We are moving away from writing strict parsing logic and toward Adaptive Normalization.
Inspired by how modern data warehouses like Snowflake handle semi-structured data and schema evolution, this approach uses low-cost LLMs as a "universal adapter" layer. Instead of breaking when data drifts, the system adapts, cleans, and standardizes it on the fly.
The Problem: Schema Drift and Maintenance Debt
For a Data Analyst, "Data Integrity" often means saying "No" to messy data sources. We force teams to use strict templates. But in reality, business operations are messy.
- Upstream Changes: A sales tool adds a custom field.
- Inconsistent Entry: One region enters dates as DD/MM/YYYY, another as MM/DD/YYYY.
- API Updates: JSON structures change nesting levels.
In the current paradigm, every variation requires a manual code update in your ETL tool (Make, n8n, Fivetran). This creates high maintenance debt. You stop being an analyst and start being a pipeline mechanic.
The Forecast: The Rise of Adaptive Normalization
I predict that within the year, the standard for ingestion will shift. We will no longer define how to extract data (using RegEx or strict JSON paths); we will simply define what the output must look like.
The automation middleware (the "adapter") will use a semantic understanding of the data to force it into the required schema, regardless of the input format. This is the Adaptive Normalization model.
Comparative Analysis: Rigid vs. Adaptive
| Feature | Rigid Enforcement (Current) | Adaptive Normalization (Forecast) |
|---|---|---|
| Handling Schema Drift | Pipeline fails (Error 400/500) | Auto-correction via inference |
| Setup Time | High (Detailed mapping required) | Low (Define target schema only) |
| Maintenance Cost | High (Constant patches) | Low (Resilient to changes) |
| Processing Cost | Negligible (Compute only) | Marginal (LLM Token costs) |
How Adaptive Normalization Works
This isn't about letting AI hallucinate data. It is about using AI to map intent to structure. Here is how I see this architecture being deployed in tools like Make or n8n:
1. The Raw Ingestion
Data arrives from an unstructured or semi-structured source (e.g., an email body, a messy CSV, or a transient webhook).
2. The Target Schema Definition
Instead of writing parsing code, the Data Analyst defines a Pydantic model or a JSON Schema that represents the perfect dataset required for the warehouse.
3. The Semantic Transformation Layer
The automation passes the raw data and the target schema to a model (like GPT-4o). The prompt is strictly operational: "Extract data from [Input] and format it strictly according to [Schema]. Do not invent data. If fields are missing, set to null."
4. The Validation Gate
Before the data touches your database, a deterministic code node validates that the LLM output matches the schema types (e.g., ensuring a "Revenue" field is actually a number).
Why Now? The Economic Tipping Point
Previously, running every row of a CSV through GPT-4 was cost-prohibitive. But with the massive price drop in "intelligent-enough" models, the cost of processing a record is now often lower than the cost of the engineering time required to fix a broken pipeline.
If an automated correction costs $0.001 per record, but saves five hours of a Data Analyst's week, the ROI is immediate.
Strategic Implications for Data Teams
This shift changes the value proposition of the Data Analyst:
- From Gatekeeper to Enabler: You no longer have to reject data sources because they are "too messy." You can ingest a wider variety of data into your BI tools.
- Focus on Definition, Not Parsing: Your skill set shifts towards defining robust data models (what the data should be) rather than writing RegEx (how to find the data).
- Increased Uptime: Dashboards become more reliable because the pipelines are self-healing against minor format changes.
Conclusion
We are moving toward a future where data pipelines are resilient by default. The Adaptive Normalization approach acknowledges that the world is messy, but insists that our databases don't have to be.
By leveraging the falling cost of semantic processing, we can build systems that bend rather than break. For the Data Analyst, this means less time fixing "janitorial" errors and more time delivering the insights that drive the business forward.
References
- Snowflake, "Schema Evolution in Snowflake": https://docs.snowflake.com/en/user-guide/data-load-schema-evolution
- dbt, "The Modern Data Stack": https://www.getdbt.com/blog/future-of-the-modern-data-stack

