Teardown: GitLab’s Handbook-First Strategy & The Semantic Deflection Process
The Hidden Tax of Internal Operations
One of the most persistent friction points I see in scaling organizations is the linear relationship between headcount and internal support volume. As you add employees, the burden on HR, IT, and Ops to answer questions grows disproportionately. The standard response is to hire more support staff or implement a ticketing system (Jira, Asana, ServiceNow).
However, a ticketing system often just organizes the backlog without reducing it.
I have been studying how GitLab approaches this. They are famous for their radical "Handbook-First" approach, championed by co-founder Sid Sijbrandij. Their rule is simple: if the answer isn't in the handbook, it doesn't exist. But writing documentation is only half the battle; the real struggle is getting employees to read it before interrupting a human colleague.
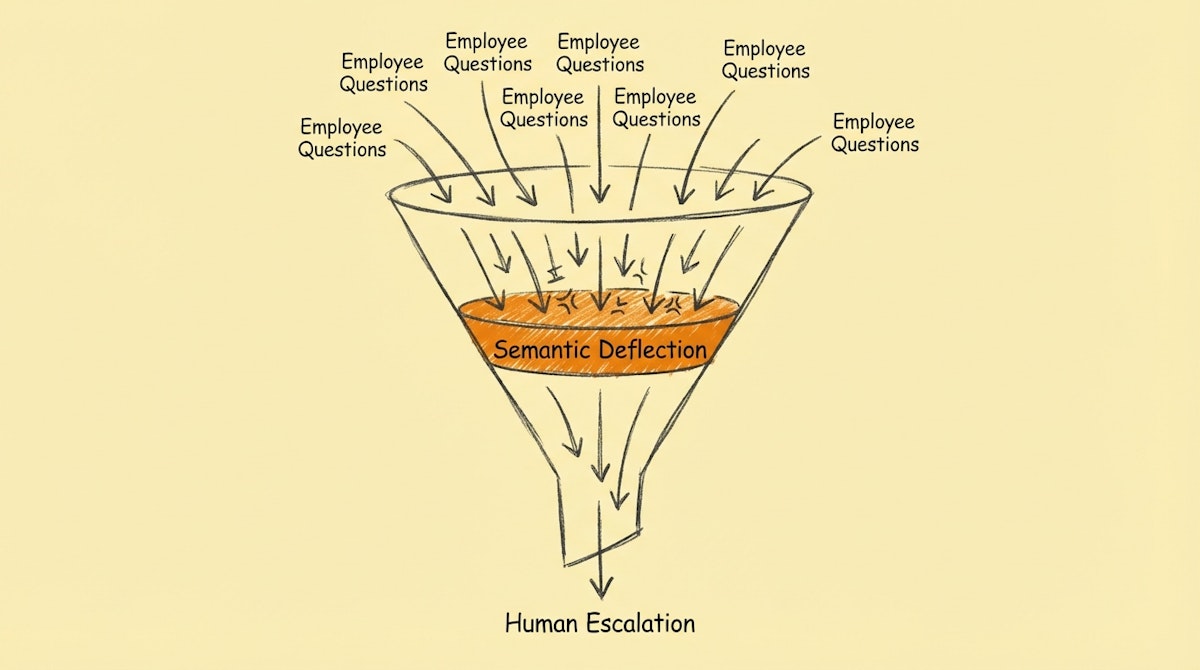
This is where the Semantic Deflection Process comes in. It is a technical layer that enforces the handbook-first culture by intercepting questions and attempting to answer them via automation before they ever reach a human queue.
The Logic: Deflection vs. Resolution
The goal of this process is not necessarily to resolve complex issues (like a broken laptop), but to deflect the high-volume, low-value queries (like "what is the wifi password" or "how do I expense a lunch").
When implemented correctly using tools like n8n or Make, alongside a vector database (like Pinecone or even Airtable with scripts), this architecture changes the unit economics of internal support.
| Metric | Manual Ticketing | Semantic Deflection |
|---|---|---|
| Time to First Response | Hours / Days | Seconds |
| Marginal Cost | ~$25 (Human time) | ~$0.05 (API costs) |
| Knowledge Base | Often ignored | Active enforcement |
Step 1: The Ingestion Pipeline
The foundation of this system is ensuring your LLM knows what your internal policy actually is. You cannot rely on the model's training data; you need RAG (Retrieval-Augmented Generation).
In a typical setup using Make or n8n:
- Trigger: A scheduled automation runs every night.
- Action: It scrapes updated pages from your internal wiki (Notion, Confluence, or Google Docs).
- Process: It chunks the text and generates embeddings using OpenAI’s
text-embedding-3-small. - Storage: These vectors are stored in a database (Pinecone is standard, though Supabase or Weaviate work well for self-hosted options).
This ensures that when an employee asks a question, the system is querying the "truth" as of last night, not a hallucination.
Step 2: The Interception Layer
This is the user-facing component. Instead of asking employees to "search the wiki" (which they rarely do efficiently), you meet them where they work: Slack or Microsoft Teams.
When a message is posted in a support channel (e.g., #ask-hr):
- The automation platform captures the event via webhook.
- It creates a Semantic Lookup against your vector database to find the most relevant handbook paragraphs.
- It passes the user's question and the retrieved context to an LLM (GPT-4o or Claude 3.5 Sonnet).
Crucially, the system prompt must be instructed to be conservative. If the relevance score of the retrieved documents is below a certain threshold (e.g., 0.75), the system should stay silent and let a human answer. Silence is better than a wrong answer.
Step 3: The Escalation Protocol
Automation is not about removing humans entirely; it's about filtering the noise so humans can focus on the signal.
The output of the LLM is posted as a threaded reply. The message should include two buttons (using Slack Block Kit):
- "✅ This helped"
- "❌ I still need help"
If the user clicks "I still need help", the automation triggers the legacy protocol: it creates a ticket in Jira/Asana and tags the support team. This feedback loop is vital. Every time a user clicks "I still need help", you log that interaction. This becomes a "content gap analysis" report—telling you exactly which parts of your handbook are missing or unclear.
Conclusion: ROI is in the Agility
The strategic value here isn't just saving 15 minutes of an HR manager's time. It is about scalability.
If you successfully deploy a Semantic Deflection Process, you decouple your company's growth from your support overhead. You allow your internal operations to remain lean while the rest of the company scales. It transforms your internal documentation from a static archive into an active, defensive layer that protects your team's focus.
References
- GitLab Handbook Usage: https://about.gitlab.com/handbook/usage/
- OpenAI Embeddings Documentation: https://platform.openai.com/docs/guides/embeddings
- Make.com Slack Integration: https://www.make.com/en/integrations/slack

