Counter-Intuitive: The Uncanny Valley Of AI Copy & The Research-First Process
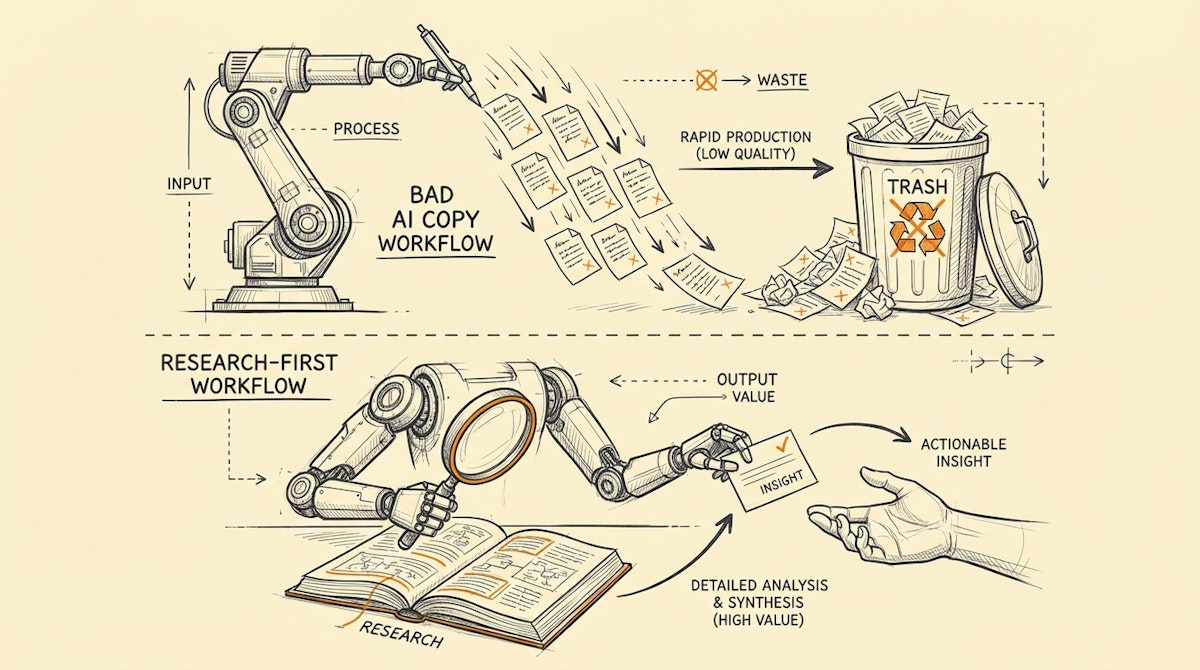
The Trap: Automating The Wrong Bottleneck
If you hang around the growth engineering circles on X (formerly Twitter) or LinkedIn, the prevailing narrative is seductive: "Connect GPT-4 to your email sequencer, generate unique intros for 10,000 leads, and watch the meetings roll in."
I admit, I’ve been tempted. The promise of infinite, personalized scaling is the holy grail for anyone in an operational role. But having observed the results of these "Hyper-Personalized" campaigns, I’m noticing a worrying trend. They aren't generating trust; they are generating noise.
We are rapidly entering the "Uncanny Valley" of text. This is a concept originally from robotics, where a humanoid robot that looks almost real—but not quite—evokes a feeling of revulsion rather than empathy. The same is happening with AI-generated outreach. When a prospect reads an email that is structurally perfect but contextually slightly "off," their spam radar flares up. They don't just ignore you; they distrust you.
The Contrarian View: Context Over Content
The contrarian view I want to propose is this: Stop using AI to write. Start using AI to read.
In our quest for efficiency, we are automating the wrong part of the workflow. Writing a good email isn't actually the bottleneck—understanding who you are writing to is.
True operational efficiency for a Growth Engineer isn't about how many emails you can blast per hour. It's about the Signal-to-Noise Ratio. Instead of automating the output (the copy), we should be automating the input (the research). By shifting the focus, we move from a "Spray and Pray" model to a "Sniper" model, which is far more sustainable and, crucially, easier to align with GDPR and privacy standards since you aren't feeding PII into a black-box generator to create public-facing communications.
The Solution: The Research-First Enrichment Process
This workflow flips the standard automation script. Instead of using Large Language Models (LLMs) to generate creative text, we use them as Semantic Analysts.
The goal is to populate a rigid, high-quality, human-written template with highly specific data points that mere deterministic lookups (like Clearbit or Apollo) cannot provide.
Phase 1: The Agentic Scraper
Most growth stacks rely on static databases. The problem is that database fields like "Industry" or "Tech Stack" are often outdated.
In this phase, we use an automation tool (like Make or n8n) to trigger an "Agentic Scraper"—a script that visits the prospect's website or LinkedIn profile in real-time. We aren't just looking for keywords; we are looking for recent context.
- Action: Scrape the "Careers" page.
- Goal: Identify active hiring cycles for specific roles (e.g., "Senior DevOps Engineer").
Phase 2: Semantic Classification (The Analyst)
Once we have the raw text from the scrape, we pass it to an LLM (like GPT-4o or Claude 3.5 Sonnet) with a strict prompt. We do not ask it to write an email. We ask it to categorize the company based on our specific criteria.
For example, if we are selling a compliance tool, we ask: "Based on their job listings, does this company appear to be expanding into the EU market? Return JSON: { expansion_detected: boolean, evidence: string }."
This turns unstructured web data into structured, actionable boolean flags.
Phase 3: The Static Router
This is where the "Uncanny Valley" is avoided. We do not generate the message. We use the boolean flags from Phase 2 to route the contact to a pre-written, human-crafted template.
If expansion_detected = true, they get Template A: "I noticed you're hiring for an EU-based Legal Counsel...".
Because the template is human-written, the tone is perfect. Because the trigger is AI-verified, the relevance is high. You get the scale of automation with the safety of manual copy.
Comparing The Approaches
Here is how the Research-First approach stacks up against the typical Generative approach.
| Metric | Generative Approach (Common) | Research-First Process (Recommended) |
|---|---|---|
| Primary AI Role | Copywriter (Creative) | Analyst (Logical) |
| Trust / Reputation Risk | High (Uncanny Valley) | Low (Human Template) |
| Data Consistency | Unpredictable (Hallucinations) | Structured (Boolean/Enum) |
| Setup Complexity | Low (Prompt & Send) | High (Scraping & Logic) |
Implementation Strategy
To build this, you don't need a massive engineering team. You need a low-code orchestration tool and a change in mindset.
- Define Your Triggers: What specific piece of information would make your outreach 100% relevant? (e.g., A new technology installed, a specific hire, a recent funding round).
- Build the Scraper: Use Puppeteer via n8n or an API like Perplexity to fetch the raw data.
- Strict Prompting: Design your LLM system prompt to act as a data cleanser, not a creative writer. Use
json_modeto ensure the output can be parsed programmatically. - The "Draft-and-Verify" Loop: Initially, don't send automatically. Have the system create a draft in your CRM. Review the logic. Once the "Analyst" AI hits >95% accuracy in categorization, turn on auto-sending.
Conclusion
The goal of operational efficiency isn't just to move faster; it's to move smarter. By resisting the temptation to let AI write for you, and instead forcing it to research for you, you build a growth engine that is resilient, high-converting, and respectful of your prospects' attention.
Avoid the Uncanny Valley. Keep the "Human" in the communication, and put the "Robot" in the research.

