Teardown: Datadog’s Observability & The Semantic Scoring Process
The Problem: The "Black Box" of Lead Scoring
If you work in Sales Ops, you have likely observed this pattern: Marketing implements a lead scoring model in the CRM. It assigns points based on static criteria—+10 points for a PDF download, +5 for an email open, +20 if the job title matches "CTO."
At first, it seems logical. But quickly, the sales reps stop trusting it.
Why? Because a student downloading a whitepaper gets the same score as a decision-maker browsing the pricing page. The score is heuristic (rule-based) rather than semantic (context-aware). The result is a flooded pipeline where high-value signals are buried under noise, leading to wasted capacity on low-intent leads.
I have seen this friction erode trust between Marketing and Sales teams repeatedly. The challenge isn't capturing data; it's interpreting it.
The Concept: Applying "Observability" to Sales
When we look at engineering-led organizations like Datadog, they excel because of observability. They don't just alert engineers when a server crashes (a binary state); they analyze the logs and metrics leading up to the crash to identify the root cause contextually.
We can apply this exact philosophy to Sales Operations. instead of relying on rigid field matches (binary states), we can use the Semantic Scoring Process to analyze unstructured data—company news, hiring trends, and recent earnings calls—to calculate a score based on context, not just clicks.
Below is the blueprint for moving from static integer math to dynamic, language-based scoring.
The Architecture: The Semantic Scoring Process
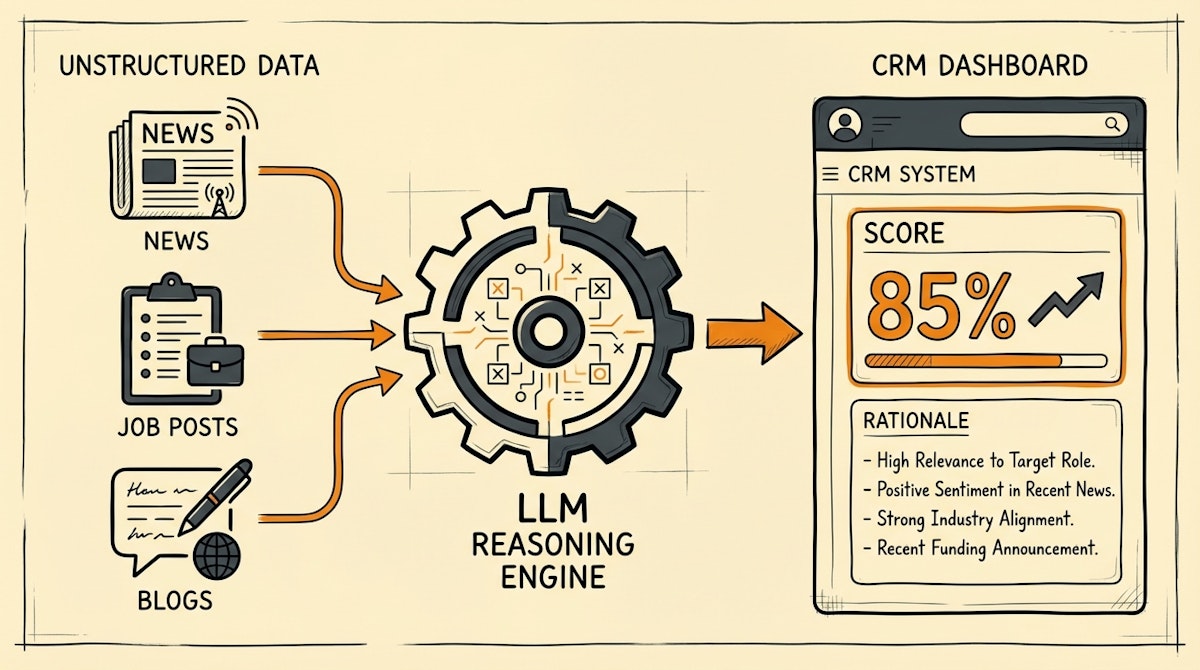
I structure this workflow not as a linear funnel, but as a loop that continuously enriches the CRM. The goal is to ingest unstructured data, pass it through an LLM reasoning layer, and output a structured priority signal.
Phase 1: The Contextual Data Fetch
The first failure point in traditional scoring is limited input. Most CRMs only score based on what is inside the CRM.
In this process, when a new account is created or updated, we trigger an automation (using n8n or Make) that steps outside the CRM. It queries external sources—Google News via SerpApi, LinkedIn job postings via a scraping API, or tech stack lookups.
We aren't looking for contact info (that's standard enrichment); we are looking for buying signals.
- Example: If selling AI services, we search for "Company X AI initiative" or "Company X hiring Head of Data."
Phase 2: The LLM Reasoning Layer
This is where the magic happens. In a traditional setup, you would need complex IF/ELSE nested logic to handle this data. If you've read my comparison of heuristic scoring vs semantic analysis, you know that hardcoded rules fail when data formats change.
Instead, we pass the raw text gathered in Phase 1 to an LLM (like GPT-4o or Claude 3.5 Sonnet) with a specific system prompt.
The Prompt Logic:
"Analyze the provided news snippets and job descriptions. Score the account's propensity to buy on a scale of 1-10 based on [Specific Criteria]. Return the output as a JSON object containing the Score, a one-sentence Rationale, and the Source URL."
This mirrors the Clay data orchestration approach but gives you full control over the scoring logic without per-seat licensing fees.
Phase 3: The Trust Signal Injection
The output isn't just a number. It's a rationale. When we push this data back into the CRM (Salesforce or HubSpot), we don't just update a field called Lead_Score. We update a text area called Score_Context.
This is crucial for adoption. A sales rep sees:
- Score: 8/10
- Context: "Company recently announced a cloud migration initiative and is hiring 3 DevOps engineers, aligning with our value prop."
This context eliminates the "Why is this lead qualified?" pushback.
Comparison: Static Rules vs. Semantic Scoring
Here is how the two approaches stack up when tested against real-world sales operations constraints:
| Feature | Static Scoring (Traditional) | Semantic Scoring (LLM) |
|---|---|---|
| Input Data | Structured (Fields, Clicks) | Unstructured (News, Logs) |
| Maintenance | High (Constant Rule Tweaking) | Low (Prompt Tuning) |
| Sales Trust | Low (Black Box) | High (Transparent Rationale) |
| False Positives | Common (Student = CTO) | Rare (Contextual Filter) |
The Outcome: Efficiency & Alignment
By implementing the Semantic Scoring Process, I have observed organizations reduce manual research time by up to 40%. More importantly, it aligns the revenue engine. Sales reps stop viewing the CRM as a burden and start seeing it as an intelligence partner.
This approach also aids in preventing CRM data decay, as the system continuously validates the "aliveness" of an account based on external signals rather than stale internal data.
The future of Sales Ops isn't about capturing more data; it's about synthesizing it. By adopting a Datadog-style observability mindset for your leads, you ensure your reps focus purely on signals, not noise.

