Teardown: Netflix’s Reliability & The Circuit Breaker Pattern for Growth Ops
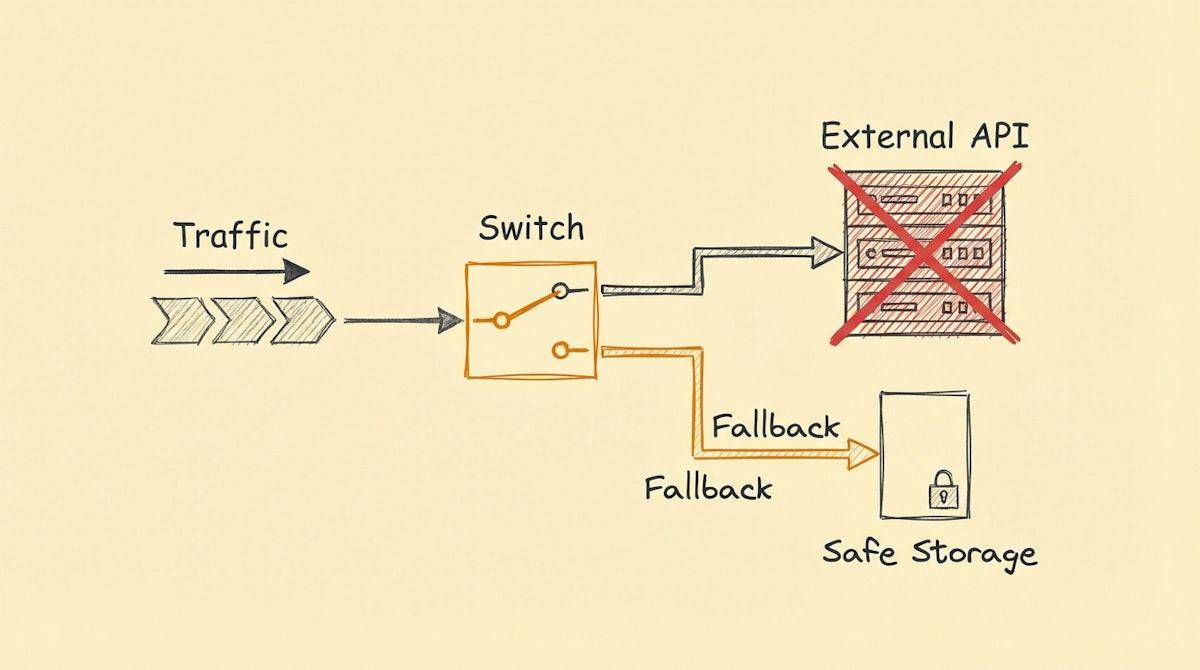
In software engineering, specifically within the microservices architecture that Netflix popularized, there is a concept called the Circuit Breaker Pattern. The logic is relatively simple: when a service fails repeatedly (e.g., an enrichment API or an AI generator), the system should stop trying to call it immediately. Instead of retrying until the system hangs or quotas are drained, the circuit "opens," preventing further calls and returning a fallback value or an error notification instantly.
For the Growth Engineer, this concept is often missing from low-code automation strategies. We tend to rely on the native "Retry" modules found in tools like Make or n8n. While retries handle transient glitches, they exacerbate persistent outages. If your lead scoring API goes down or your OpenAI prompt starts hallucinating structural errors, a standard retry policy will simply queue up thousands of executions, burn through your API credits, and potentially clog your entire operation.
This blueprint explores how to implement a Circuit Breaker Architecture within growth workflows to ensure system resilience and govern external dependencies.
The Problem: Cascading Failures in Growth Stacks
Most growth stacks are fragile because they rely on synchronous chains of events. A user signs up -> Clearbit enriches data -> GPT drafts an email -> Customer.io sends it.
If the enrichment step hangs or errors out 50% of the time, two things happen:
- Resource Exhaustion: Your automation tool keeps threads open, waiting for timeouts, which can hit concurrency limits.
- Quota Waste: If the error is due to a bad request structure, retrying 3 times means you pay 3 times for the same failure.
Unlike a simple error handler, a Circuit Breaker monitors the health of the process. If the failure rate exceeds a threshold (e.g., 5 failures in 1 minute), it cuts off access to that specific step for all subsequent runs until a cooling-off period passes.
The Blueprint: The State-Aware Circuit Breaker
To implement this in a low-code environment (Make, n8n), we cannot rely solely on the workflow logic itself, because each execution is stateless—it doesn't know that the previous 10 runs failed. We need an external State Registry.
Core Components:
- The State Registry (Redis / Airtable / Data Store): A lightweight database that holds the status of your external services. It tracks variables like
status(Closed, Open, Half-Open) andfailure_count. - The Guard Rail (Router): The first step in your critical workflow. It checks the Registry. If the status is "Open" (broken), it immediately routes to a Fallback path. If "Closed" (healthy), it proceeds.
- The Execution & Monitor: The actual API call. If it succeeds, it resets the
failure_count. If it fails, it increments the count. - The Tripper Logic: A separate, asynchronous check. If
failure_count> Threshold, it updates the status to "Open" and timestamps it. - The Fallback Mechanism: When the circuit is open, this path executes a default action (e.g., assigning a generic lead score, skipping enrichment, or alerting the Ops team) without attempting the failing API.
Architectural Comparison
I have observed that teams often confuse "Error Handling" with "Circuit Breaking." The table below outlines the difference in impact on your operations.
| Feature | Standard Retry / Error Handler | Circuit Breaker Pattern |
|---|---|---|
| Response to Outage | Retries repeatedly per execution | Stops all traffic instantly |
| API Quota Impact | High (Multiplies calls) | Minimal (Zero calls during outage) |
| User Experience | Long delays / Timeouts | Instant Fallback (Graceful degradation) |
| System Load | Spikes during failures | Remains flat |
Implementing the "Half-Open" State
The nuance of this pattern—and where I see the most value for Growth Engineers—is the recovery phase, known as the Half-Open state.
You cannot leave the circuit broken forever. In the State Registry, you define a timeout (e.g., 10 minutes). After this time passes, the Guard Rail allows one single request to pass through.
- If it succeeds: The external service is back up. The Registry resets to "Closed" (Healthy), and traffic resumes normally.
- If it fails: The service is still down. The timer resets, and the circuit remains "Open."
This self-healing mechanism is critical for maintaining high-volume lead pipelines without constant manual intervention.
Strategic Value: Graceful Degradation
The ultimate goal of this architecture is Graceful Degradation. In a growth context, it is often better to have a lead with partial data (e.g., missing Clearbit enrichment) inside the CRM immediately, rather than a lead stuck in an automation queue for 4 hours waiting for an API to recover.
By adopting the Circuit Breaker pattern, you shift from a fragile, binary outcome (Success vs. Total Failure) to a resilient operation that maintains throughput even when individual components degrade.
References
- Netflix Tech Blog: Fault Tolerance in a High Volume Distributed System
- Martin Fowler: Circuit Breaker Pattern

