Assembling the Composable Financial Ingestion Toolkit for Unstructured Data
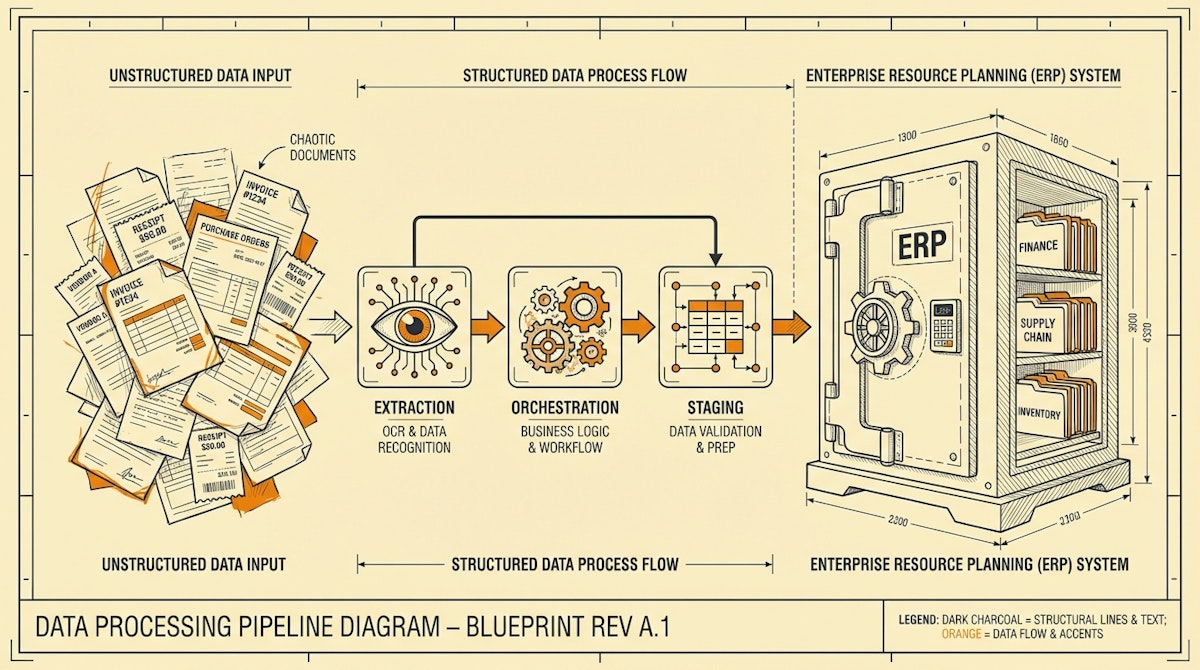
The gap between the pristine environment of an ERP and the chaotic reality of business operations is where most financial teams lose their weekends. While the General Ledger demands absolute precision, the inputs—PDF invoices, email confirmations, Stripe receipts, and Slack approval messages—are inherently messy and unstructured.
From what I have observed in the industry, the instinct is often to force the ERP to handle this ingestion. However, legacy systems like SAP, NetSuite, or even modern ones like Xero are designed for storage and reporting, not for the agile transformation of unstructured data. They are systems of record, not systems of engagement.
To solve this, a "Composable Financial Ingestion Toolkit" is required. This is an architectural approach akin to the "Modern Data Stack" philosophy popularized by data engineers, but adapted for finance operations. It focuses on inserting a middleware layer that extracts, cleans, and structures data before it ever touches the accounting software.
The Core Philosophy: The Staging Area
Before discussing specific tools, it is vital to understand the architectural requirement: The Staging Layer.
Writing automation that posts directly from an email parser to the General Ledger is a recipe for disaster. If the AI hallucinates an invoice amount or a vendor name, the error is codified in the ledger, requiring a complex reversal process to fix. The toolkit must be built around a "Draft State" or a Staging Database where data sits, waits for validation, and only moves to the ERP when it meets strict integrity criteria.
Component 1: The Intelligent Extraction Layer
Traditional OCR (Optical Character Recognition) was template-based and rigid. If a vendor changed their invoice layout, the automation broke. The modern toolkit replaces template-based OCR with Multimodal LLMs.
Recommended Tools:
- GPT-4o (OpenAI) or Claude 3.5 Sonnet (Anthropic): These models possess vision capabilities that allow them to "read" a PDF or image not just for text, but for context. They can distinguish between a "Total" and a "Subtotal" based on layout logic, even if the coordinates change.
- Document Parsing APIs (e.g., Mindee or Rossum): For high-volume environments where pure LLM costs might scale poorly, specialized APIs offer a middle ground between rigid templates and fluid AI.
Component 2: The Orchestration & Transformation Engine
This is the nervous system of the toolkit. It receives the raw file, sends it to the extraction layer, applies logic (e.g., "If amount > $500, check approval policy"), and routes the data.
Recommended Tools:
- n8n: I often lean towards n8n for financial use cases because it is self-hostable. Financial data privacy is paramount, and being able to run the orchestration on your own infrastructure (rather than a shared cloud) is a significant compliance advantage.
- Make: For teams less concerned with self-hosting or dealing with lower sensitivity data, Make provides a more visual, rapid-deployment environment.
Component 3: The Staging & Validation Database
This is the "Airlock" where data is held. It acts as the interface for the Financial Controller to review exceptions.
Recommended Tools:
- Airtable / SmartSuite: These serve as excellent "Human-in-the-Loop" interfaces. They allow the automation to populate rows with extracted data (Date, Vendor, Amount, Category) and attach the source PDF. The Controller simply reviews and clicks a "Sync to ERP" button (triggering a webhook) to finalize the transaction.
- Supabase (PostgreSQL): For higher volumes where a spreadsheet UI is insufficient, a raw SQL database offers better data integrity and querying speed.
Comparison: Legacy vs. Composable Ingestion
| Feature | Legacy OCR / ERP Module | Composable Toolkit (LLM + n8n) |
|---|---|---|
| Flexibility | Low (Requires Templates) | High (Context Aware) |
| Control | Black Box | Granular (Staging Layer) |
| Cost Model | Per User / License | Usage Based |
Connecting to the ERP
The final mile is the API connection to the system of record (QuickBooks, Xero, NetSuite). The key here is idempotency—ensuring that if the automation runs twice by accident, it does not create duplicate entries. The Staging Layer helps prevent this by maintaining a unique ID for every transaction before it is pushed.
Conclusion
The goal of this toolkit is not just to save time on data entry. It is to create a standardized data pipeline that turns the chaotic flow of financial documents into a structured, predictable stream. By decoupling extraction from accounting, you gain the ability to swap out components (e.g., changing LLM providers) without disrupting the core accounting logic.

