Contrarian: Abandoning Strict Validation For The Asynchronous Enrichment Process
We need to talk about the "Garbage In, Garbage Out" dogma. In the world of Sales Operations, this mantra has driven us to build CRMs that behave like fortresses. We add validation rules, required fields, and complex stage-gating logic to ensure that if data enters the system, it is pristine.
But I have observed a recurring paradox: the stricter the validation rules, the less the CRM reflects reality.
When faced with a mandatory "Competitor" field at the early "Discovery" stage, a busy sales rep doesn't conduct deep research. They select "Other" or "Unknown" just to move the deal forward. We trade user experience for the illusion of data integrity.
This is a controversial take, but I believe the traditional approach to CRM discipline—forcing structure at the point of entry—is becoming obsolete. With the capabilities of modern LLMs (like GPT-4 or Claude 3) and automation platforms (Make, n8n), we should be shifting towards an Asynchronous Enrichment Process.
The Problem: Friction Kills Data Velocity
The goal of the Sales Ops Manager is often split between two opposing forces:
- Reporting Accuracy: Requiring structured data to forecast revenue.
- Sales Velocity: Removing administrative hurdles so reps can sell.
Usually, Reporting Accuracy wins. We force reps to become data entry clerks. The result isn't just annoyed salespeople; it's "Shadow Ops." Reps keep their real notes in Apple Notes, Excel, or sheer memory, only updating the CRM at the very last minute (or 5 minutes before the QBR).
This leads to Data Latency. Your forecast is technically "clean" (the fields are filled), but it is weeks out of date.
The Solution: The Asynchronous Enrichment Process
Instead of blocking the input until it is perfect, we should accept "messy" input and clean it post-ingestion. This approach leverages the ability of Large Language Models to parse unstructured text into structured JSON, which can then be mapped to your CRM fields.
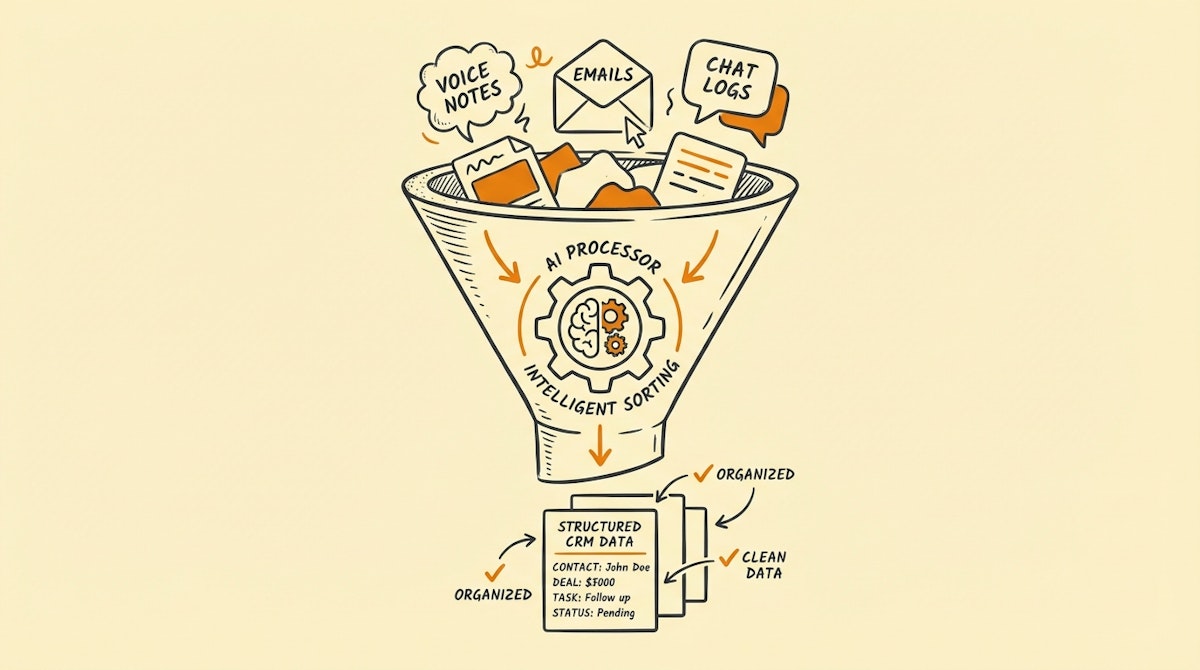
Here is how I visualize this architecture:
1. The "Low-Friction" Capture Layer
Allow reps to dump raw information where they already work. This could be:
- Voice Notes: A quick audio recording after a meeting.
- Slack/Teams: A dedicated channel where they type "Just met with Acme Corp, they are worried about pricing but love the API."
- Email Forwarding: Forwarding the client thread to a webhook.
At this stage, there are zero validation rules.
2. The "Janitor" Agent (Automation)
This is where tools like Make or n8n come in. The workflow triggers on the new entry:
- Ingest: Receives the raw text/audio.
- Transcribe: (If audio) Uses OpenAI Whisper to convert to text.
- Structure: Sends the text to an LLM with a specific prompt: "Extract the client sentiment, identified competitors, and potential deal size from this text. Output as JSON."
- Enrich: The automation updates the CRM record (Salesforce, HubSpot, Pipedrive) with these structured values.
3. The "Human-in-the-Loop" Verification
Rather than forcing the rep to input data, we ask them to verify it. After the enrichment runs, the automation sends a Slack message to the rep:
"I updated the Acme Corp deal. I marked 'Competitor' as 'Stripe' and 'Sentiment' as 'High'. Is this correct?"
The rep simply clicks "Yes" or replies with a correction. It changes the dynamic from Data Entry to Data Review.
Comparing The Approaches
Below is a breakdown of how shifting the burden of structure from human to machine impacts operations.
| Metric | Strict Validation (Traditional) | Asynchronous Enrichment (AI) |
|---|---|---|
| Rep Experience | High Friction (Gatekeeper) | Low Friction (Invisible) |
| Data Latency | High (Updates delayed) | Low (Real-time capture) |
| Data Quality source | Forced Compliance | Semantic Extraction |
| Ops Role | Enforcer / Police | Architect / Auditor |
Implementation Nuances
Implementing this requires a mindset shift. You are essentially building a "staging area" for your data.
One technical risk I have observed is hallucination—the AI inferring a competitor when none was mentioned. To mitigate this, I recommend using the "Unknown" default strategy. Instruct the LLM in the system prompt to return null or "Unknown" if the information is not explicitly present, rather than guessing.
Furthermore, this aligns with the concept of Revenue Intelligence popularized by companies like Gong. They realized early on that analyzing the conversation is more valuable than analyzing the manual CRM entry. We are simply democratizing this capability using low-code tools.
Conclusion
It is tempting to think that "more rules = better data." But in a human-centric system like Sales, the opposite is often true. By removing barriers to entry and relying on backend processing to clean the mess, you might find that your CRM finally starts to reflect the reality of your business.
Stop training your high-value sales reps to be mediocre database administrators. Let them sell, and let the automation handle the paperwork.

