Teardown: Amazon PR/FAQ turns automation into measurable value
Teardown: Amazon’s PR/FAQ, re-used for internal ops automation ROI
The problem I keep seeing in internal ops automation
Automation requests arrive as scattered pings: “can we auto-route these emails?”, “can we sync this spreadsheet?”, “can we use an LLM to draft replies?”. The build is usually the easy part.
The hard part is value: why we’re doing this, what we expect to change, and how we’ll prove it changed. When that stays fuzzy, you get pilot purgatory, brittle workflows nobody trusts, and a backlog that’s impossible to prioritize.
This is where I like stealing a page from Amazon.
Teardown: what Amazon’s PR/FAQ is really doing
Amazon describes “Working Backwards” as a systematic way to vet ideas by starting with the customer experience, then iterating until the team has clarity on what to build. Its core artifact is the PR/FAQ: a press release plus frequently asked questions, written before the build. (Working Backwards overview, PR/FAQ concept). (About Amazon)
Two details matter for ops work:
It forces crisp intent. A press release headline is binary: either it says something meaningful, or it doesn’t.
It creates a reviewable artifact. Amazon’s writing culture is explicit: no slides; written narratives are read at the start of meetings (“study hall”). (2017 shareholder letter excerpt). (About Amazon)
In other words: the win isn’t “better docs.” The win is better decisions because the Process makes weak thinking expensive.
The mapping: treat each automation like an internal product
For an Internal Ops Manager, your “customers” are colleagues. Your “product” is a process change wrapped in software. That means you can adapt the PR/FAQ idea directly:
Press release → the promised outcome (faster cycle time, fewer errors, less risk, less toil)
FAQ → the skepticism list (edge cases, dependencies, adoption, failure modes)
Launch metrics → the value ledger (baseline → target → measured impact)
This aligns with what value-focused AI research keeps repeating: practices that support strategy, operating model, and adoption correlate with value capture—not just experimentation. (McKinsey State of AI 2025). (McKinsey & Company)
The Working-Backwards Value Ledger Process
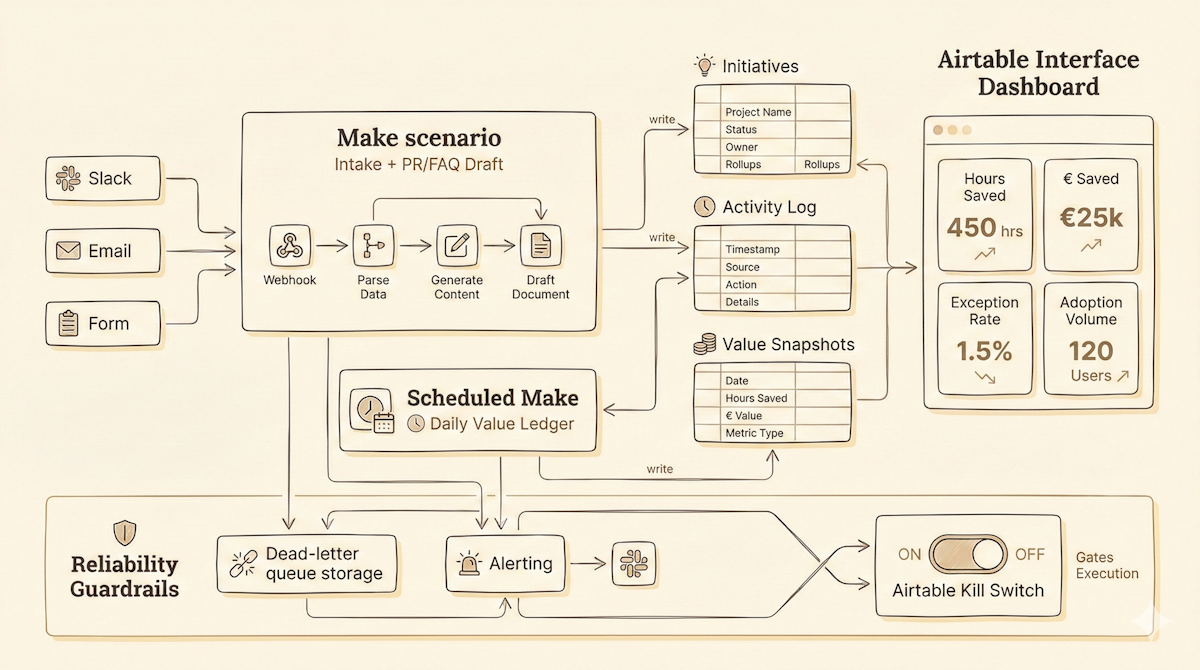
Here’s a simplified blueprint using Airtable + Make (LLM provider swappable). I call it the Working-Backwards Value Ledger Process.
Step 1: Intake that produces a draft PR/FAQ (not a ticket)
Tooling: Airtable Form → Make scenario → (optional) LLM module
Requester submits: “what hurts”, “who it hurts”, “how often”, “what ‘better’ looks like”.
Make creates an Initiative record in Airtable.
If you use an LLM, have it generate:
a 1-sentence “press release headline”
5–8 FAQ bullets (risks, dependencies, failure modes)
3 candidate metrics (time, quality, cost/risk)
Outcome: every request becomes a decision-ready object, not backlog noise.
Step 2: Baseline capture in the same record
Most ROI arguments die because nobody measured “before.” Keep it lightweight:
Pick one primary metric (cycle time, handle time, error rate, SLA miss rate).
Pick one supporting metric (rework count, exception rate, stakeholder satisfaction).
Capture baseline via either:
a 1-week sample, or
a quick time study (20–30 cases)
This is straight benefits-management logic: define benefits up front so you can track realization later. (APM sample chapter, PMI BRM framework). (APM)
Step 3: A review gate that approves measurement, not just build
Tooling: Airtable Interface (or views) → Make → Slack/Email approvals
When Initiative status becomes Review:
Make posts the PR/FAQ summary to a shared channel.
Approvers choose one:
Build (metrics + instrumentation plan is acceptable)
Revise (questions must be answered)
No (doesn’t move a meaningful needle)
This seems bureaucratic until you try it: you stop spending build time on initiatives that can’t be measured.
Step 4: Build with instrumentation as a first-class requirement
Tooling: Make scenarios + an Airtable Activity Log table
A lot of automation “ROI” is guessed because the workflow produces no useful exhaust. So: every scenario writes a log row.
Example fields:
initiative_idevent_type(created, routed, approved, exception, retry)timestamp_start,timestamp_endsuccessbooleanerror_class(timeout, validation, auth, human-needed)
Now you can compute:
volume handled
exception rate
average handling time inside the automation
failure trends that erode trust
Step 5: The value ledger (automatic, boring, consistent)
Tooling: Make scheduled job → Airtable rollups → Airtable Interface dashboard
Once per day (or week), Make:
Aggregates Activity Log events per initiative.
Updates rollups:
hours_saved = volume * (baseline_minutes - new_minutes) / 60value_saved = hours_saved * blended_hourly_costquality_gain = baseline_error_rate - current_error_rate
Writes a “Value Snapshot” record for auditability.
Keep the math explicit. If the assumptions are wrong, you want them easy to challenge.
Step 6: Reliability guardrails (because value dies when trust dies)
Tooling: Make error handlers + alerting + Airtable Incidents table
Add three guardrails by default:
Dead-letter queue: failed payloads stored for replay
Kill switch: Airtable boolean that Make checks before executing critical actions
Drift alerts: if exception rate crosses a threshold, create an incident and notify an owner
This is the non-obvious benefit that compounds: colleagues start trusting automation as infrastructure, not fragile glue.
Minimal Airtable schema you can copy
Table: Initiatives
Name, Owner, Internal customer, Frequency, Current pain
PR headline, FAQ bullets
Primary metric, Baseline, Target
Blended hourly cost (assumption), Confidence (H/M/L)
Status (Intake → Review → Build → Live → Retired)
Kill switch (boolean)
Table: Activity Log
Initiative (link), Event type, Start, End, Success, Error class, Payload link
Table: Value Snapshots
Initiative (link), Period, Volume, Hours saved, € saved, Exception rate, Notes
Two ways to run this, depending on your reality
Lean mode (small team): 1 metric, 1 snapshot per month, manual baseline sampling.
Ops-at-scale mode: multiple metrics, weekly snapshots, automated baselines from system logs, stronger governance around exceptions.
Same Process. Different measurement depth.
Closing thought
The headline benefit is ROI clarity.
The deeper benefit is operational: a shared system that makes tradeoffs visible. You get a consistent way to say yes, no, or not yet—without arguing about tools, vibes, or whoever shouted loudest.
Benefits realization guidance tends to frame this as a lifecycle: define, plan, measure, sustain. This Process just makes that lifecycle unavoidable in day-to-day ops work. (PMI “Ten Guidelines” paper). (Project Management Institute)
References
https://www.aboutamazon.com/news/workplace/an-insider-look-at-amazons-culture-and-processes
https://workingbackwards.com/concepts/working-backwards-pr-faq-process/
https://www.aboutamazon.com/news/company-news/2017-letter-to-shareholders
https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
https://www.mckinsey.com/~/media/mckinsey/business%20functions/quantumblack/our%20insights/the%20state%20of%20ai/november%202025/the-state-of-ai-in-2025-agents-innovation-and-transformation.pdf
https://www.apm.org.uk/media/y2phxpmi/benefits-management-framework-sample-chapter.pdf
https://www.pmi.org/-/media/pmi/documents/public/pdf/learning/thought-leadership/benefits-realization-management-framework.pdf
https://www.pmi.org/learning/library/guidelines-successful-benefits-realization-9909

